diff --git a/README.md b/README.md
index 357ed35..eaceeb9 100644
--- a/README.md
+++ b/README.md
@@ -18,3 +18,4 @@ $ git clone https://git.platypush.tech/platypush/blog.git
$ cd blog
$ madblog
```
+
diff --git a/config.yaml b/config.yaml
index b7a8475..ea9967c 100644
--- a/config.yaml
+++ b/config.yaml
@@ -2,7 +2,6 @@ title: Platypush
description: The Platypush blog
link: https://blog.platypush.tech
home_link: https://platypush.tech
-short_feed: True
categories:
- IoT
- automation
diff --git a/img/music-automation.png b/img/music-automation.png
deleted file mode 100644
index 36be419..0000000
Binary files a/img/music-automation.png and /dev/null differ
diff --git a/markdown/Automate-your-music-collection.md b/markdown/Automate-your-music-collection.md
deleted file mode 100644
index 3a54e80..0000000
--- a/markdown/Automate-your-music-collection.md
+++ /dev/null
@@ -1,1230 +0,0 @@
-[//]: # (title: Automate your music collection)
-[//]: # (description: Use Platypush to manage your music activity, discovery playlists and be on top of new releases.)
-[//]: # (image: /img/music-automation.png)
-[//]: # (author: Fabio Manganiello <fabio@platypush.tech>)
-[//]: # (published: 2022-09-19)
-[//]: # (latex: 1)
-
-I have been an enthusiastic user of mpd and mopidy for nearly two decades. I
-have already [written an
-article](https://blog.platypush.tech/article/Build-your-open-source-multi-room-and-multi-provider-sound-server-with-Platypush-Mopidy-and-Snapcast)
-on how to leverage mopidy (with its tons of integrations, including Spotify,
-Tidal, YouTube, Bandcamp, Plex, TuneIn, SoundCloud etc.), Snapcast (with its
-multi-room listening experience out of the box) and Platypush (with its
-automation hooks that allow you to easily create if-this-then-that rules for
-your music events) to take your listening experience to the next level, while
-using open protocols and easily extensible open-source software.
-
-There is a feature that I haven't yet covered in my previous articles, and
-that's the automation of your music collection.
-
-Spotify, Tidal and other music streaming services offer you features such as a
-_Discovery Weekly_ or _Release Radar_ playlists, respectively filled with
-tracks that you may like, or newly released tracks that you may be interested
-in.
-
-The problem is that these services come with heavy trade-offs:
-
-1. Their algorithms are closed. You don't know how Spotify figures out which
- songs should be picked in your smart playlists. In the past months, Spotify
- would often suggest me tracks from the same artists that I had already
- listened to or skipped in the past, and there's no transparent way to tell
- the algorithm "hey, actually I'd like you to suggest me more this kind of
- music - or maybe calculate suggestions only based on the music I've listened
- to in this time range, or maybe weigh this genre more".
-
-2. Those features are tightly coupled with the service you use. If you cancel
- your Spotify subscription, you lose those smart features as well.
- Companies like Spotify use such features as a lock-in mechanism -
- you can check out any time you like, but if you do then nobody else will
- provide you with their clever suggestions.
-
-After migrating from Spotify to Tidal in the past couple of months (TL;DR:
-Spotify f*cked up their developer experience multiple times over the past
-decade, and their killing of libspotify without providing any alternatives was
-the last nail in the coffin for me) I felt like missing their smart mixes,
-discovery and new releases playlists - and, on the other hand, Tidal took a
-while to learn my listening habits, and even when it did it often generated
-smart playlists that were an inch below Spotify's. I asked myself why on earth
-my music discovery experience should be so tightly coupled to one single cloud
-service. And I decided that the time had come for me to automatically generate
-my service-agnostic music suggestions: it's not rocket science anymore, there's
-plenty of services that you can piggyback on to get artist or tracks similar to
-some music given as input, and there's just no excuses to feel locked in by
-Spotify, Google, Tidal or some other cloud music provider.
-
-In this article we'll cover how to:
-
-1. Use Platypush to automatically keep track of the music you listen to from
- any of your devices;
-2. Calculate the suggested tracks that may be similar to the music you've
- recently listen to by using the Last.FM API;
-3. Generate a _Discover Weekly_ playlist similar to Spotify's without relying
- on Spotify;
-4. Get the newly released albums and single by subscribing to an RSS feed;
-5. Generate a weekly playlist with the new releases by filtering those from
- artists that you've listened to at least once.
-
-## Ingredients
-
-We will use Platypush to handle the following features:
-
-1. Store our listening history to a local database, or synchronize it with a
- scrobbling service like [last.fm](https://last.fm).
-2. Periodically inspect our newly listened tracks, and use the last.fm API to
- retrieve similar tracks.
-3. Generate a discover weekly playlist based on a simple score that ranks
- suggestions by match score against the tracks listened on a certain period
- of time, and increases the weight of suggestions that occur multiple times.
-4. Monitor new releases from the newalbumreleases.net RSS feed, and create a
- weekly _Release Radar_ playlist containing the items from artists that we
- have listened to at least once.
-
-This tutorial will require:
-
-1. A database to store your listening history and suggestions. The database
- initialization script has been tested against Postgres, but it should be
- easy to adapt it to MySQL or SQLite with some minimal modifications.
-2. A machine (it can be a RaspberryPi, a home server, a VPS, an unused tablet
- etc.) to run the Platypush automation.
-3. A Spotify or Tidal account. The reported examples will generate the
- playlists on a Tidal account by using the `music.tidal` Platypush plugin,
- but it should be straightforward to adapt them to Spotify by using the
- `music.spotify` plugin, or even to YouTube by using the YouTube API, or even
- to local M3U playlists.
-
-## Setting up the software
-
-Start by installing Platypush with the
-[Tidal](https://docs.platypush.tech/platypush/plugins/music.tidal.html),
-[RSS](https://docs.platypush.tech/platypush/plugins/rss.html) and
-[Last.fm](https://docs.platypush.tech/platypush/plugins/lastfm.html)
-integrations:
-
-```
-[sudo] pip install 'platypush[tidal,rss,lastfm]'
-```
-
-If you want to use Spotify instead of Tidal then just remove `tidal` from the
-list of extra dependencies - no extra dependencies are required for the
-[Spotify
-plugin](https://docs.platypush.tech/platypush/plugins/music.spotify.html).
-
-If you are planning to listen to music through mpd/mopidy, then you may also
-want to include `mpd` in the list of extra dependencies, so Platypush can
-directly monitor your listening activity over the MPD protocol.
-
-Let's then configure a simple configuration under `~/.config/platypush/config.yaml`:
-
-```yaml
-music.tidal:
- # No configuration required
-
-# Or, if you use Spotify, create an app at https://developer.spotify.com and
-# add its credentials here
-# music.spotify:
-# client_id: client_id
-# client_secret: client_secret
-
-lastfm:
- api_key: your_api_key
- api_secret: your_api_secret
- username: your_user
- password: your_password
-
-# Subscribe to updates from newalbumreleases.net
-rss:
- subscriptions:
- - https://newalbumreleases.net/category/cat/feed/
-
-# Optional, used to send notifications about generation issues to your
-# mobile/browser. You can also use Pushbullet, an email plugin or a chatbot if
-# you prefer.
-ntfy:
- # No configuration required if you want to use the default server at
- # https://ntfy.sh
-
-# Include the mpd plugin and backend if you are listening to music over
-# mpd/mopidy
-music.mpd:
- host: localhost
- port: 6600
-
-backend.music.mopidy:
- host: localhost
- port: 6600
-```
-
-Start Platypush by running the `platypush` command. The first time it should
-prompt you with a tidal.com link required to authenticate your user. Open it in
-your browser and authorize the app - the next runs should no longer ask you to
-authenticate.
-
-Once the Platypush dependencies are in place, let's move to configure the
-database.
-
-## Database configuration
-
-I'll assume that you have a Postgres database running somewhere, but the script
-below can be easily adapted also to other DBMS's.
-
-Database initialization script:
-
-```sql
--- New listened tracks will be pushed to the tmp_music table, and normalized by
--- a trigger.
-drop table if exists tmp_music cascade;
-create table tmp_music(
- id serial not null,
- artist varchar(255) not null,
- title varchar(255) not null,
- album varchar(255),
- created_at timestamp with time zone default CURRENT_TIMESTAMP,
- primary key(id)
-);
-
--- This table will store the tracks' info
-drop table if exists music_track cascade;
-create table music_track(
- id serial not null,
- artist varchar(255) not null,
- title varchar(255) not null,
- album varchar(255),
- created_at timestamp with time zone default CURRENT_TIMESTAMP,
- primary key(id),
- unique(artist, title)
-);
-
--- Create an index on (artist, title), and ensure that the (artist, title) pair
--- is unique
-create unique index track_artist_title_idx on music_track(lower(artist), lower(title));
-create index track_artist_idx on music_track(lower(artist));
-
--- music_activity holds the listened tracks
-drop table if exists music_activity cascade;
-create table music_activity(
- id serial not null,
- track_id int not null,
- created_at timestamp with time zone default CURRENT_TIMESTAMP,
- primary key(id)
-);
-
--- music_similar keeps track of the similar tracks
-drop table if exists music_similar cascade;
-create table music_similar(
- source_track_id int not null,
- target_track_id int not null,
- match_score float not null,
- primary key(source_track_id, target_track_id),
- foreign key(source_track_id) references music_track(id),
- foreign key(target_track_id) references music_track(id)
-);
-
--- music_discovery_playlist keeps track of the generated discovery playlists
-drop table if exists music_discovery_playlist cascade;
-create table music_discovery_playlist(
- id serial not null,
- name varchar(255),
- created_at timestamp with time zone default CURRENT_TIMESTAMP,
- primary key(id)
-);
-
--- This table contains the track included in each discovery playlist
-drop table if exists music_discovery_playlist_track cascade;
-create table music_discovery_playlist_track(
- id serial not null,
- playlist_id int not null,
- track_id int not null,
- primary key(id),
- unique(playlist_id, track_id),
- foreign key(playlist_id) references music_discovery_playlist(id),
- foreign key(track_id) references music_track(id)
-);
-
--- This table contains the new releases from artist that we've listened to at
--- least once
-drop table if exists new_release cascade;
-create table new_release(
- id serial not null,
- artist varchar(255) not null,
- album varchar(255) not null,
- genre varchar(255),
- created_at timestamp with time zone default CURRENT_TIMESTAMP,
-
- primary key(id),
- constraint u_artist_title unique(artist, album)
-);
-
--- This trigger normalizes the tracks inserted into tmp_track
-create or replace function sync_music_data()
- returns trigger as
-$$
-declare
- track_id int;
-begin
- insert into music_track(artist, title, album)
- values(new.artist, new.title, new.album)
- on conflict(artist, title) do update
- set album = coalesce(excluded.album, old.album)
- returning id into track_id;
-
- insert into music_activity(track_id, created_at)
- values (track_id, new.created_at);
-
- delete from tmp_music where id = new.id;
- return new;
-end;
-$$
-language 'plpgsql';
-
-drop trigger if exists on_sync_music on tmp_music;
-create trigger on_sync_music
- after insert on tmp_music
- for each row
- execute procedure sync_music_data();
-
--- (Optional) accessory view to easily peek the listened tracks
-drop view if exists vmusic;
-create view vmusic as
-select t.id as track_id
- , t.artist
- , t.title
- , t.album
- , a.created_at
-from music_track t
-join music_activity a
-on t.id = a.track_id;
-```
-
-Run the script on your database - if everything went smooth then all the tables
-should be successfully created.
-
-## Synchronizing your music activity
-
-Now that all the dependencies are in place, it's time to configure the logic to
-store your music activity to your database.
-
-If most of your music activity happens through mpd/mopidy, then storing your
-activity to the database is as simple as creating a hook on
-[`NewPlayingTrackEvent`
-events](https://docs.platypush.tech/platypush/events/music.html)
-that inserts any new played track on `tmp_music`. Paste the following
-content to a new Platypush user script (e.g.
-`~/.config/platypush/scripts/music/sync.py`):
-
-```python
-# ~/.config/platypush/scripts/music/sync.py
-
-from logging import getLogger
-
-from platypush.context import get_plugin
-from platypush.event.hook import hook
-from platypush.message.event.music import NewPlayingTrackEvent
-
-logger = getLogger('music_sync')
-
-# SQLAlchemy connection string that points to your database
-music_db_engine = 'postgresql+pg8000://dbuser:dbpass@dbhost/dbname'
-
-
-# Hook that react to NewPlayingTrackEvent events
-@hook(NewPlayingTrackEvent)
-def on_new_track_playing(event, **_):
- track = event.track
-
- # Skip if the track has no artist/title specified
- if not (track.get('artist') and track.get('title')):
- return
-
- logger.info(
- 'Inserting track: %s - %s',
- track['artist'], track['title']
- )
-
- db = get_plugin('db')
- db.insert(
- engine=music_db_engine,
- table='tmp_music',
- records=[
- {
- 'artist': track['artist'],
- 'title': track['title'],
- 'album': track.get('album'),
- }
- for track in tracks
- ]
- )
-```
-
-Alternatively, if you also want to sync music activity that happens on
-other clients (such as the Spotify/Tidal app or web view, or over mobile
-devices), you may consider leveraging Last.fm. Last.fm (or its open alternative
-Libre.fm) is a _scrobbling_ service compatible with most of the music
-players out there. Both Spotify and Tidal support scrobbling, the [Android
-app](https://apkpure.com/last-fm/fm.last.android) can grab any music activity
-on your phone and scrobble it, and there are even [browser
-extensions](https://chrome.google.com/webstore/detail/web-scrobbler/hhinaapppaileiechjoiifaancjggfjm?hl=en)
-that allow you to keep track of any music activity from any browser tab.
-
-So an alternative approach may be to send both your mpd/mopidy music activity,
-as well as your in-browser or mobile music activity, to last.fm / libre.fm. The
-corresponding hook would be:
-
-```python
-# ~/.config/platypush/scripts/music/sync.py
-
-from logging import getLogger
-
-from platypush.context import get_plugin
-from platypush.event.hook import hook
-from platypush.message.event.music import NewPlayingTrackEvent
-
-logger = getLogger('music_sync')
-
-
-# Hook that react to NewPlayingTrackEvent events
-@hook(NewPlayingTrackEvent)
-def on_new_track_playing(event, **_):
- track = event.track
-
- # Skip if the track has no artist/title specified
- if not (track.get('artist') and track.get('title')):
- return
-
- lastfm = get_plugin('lastfm')
- logger.info(
- 'Scrobbling track: %s - %s',
- track['artist'], track['title']
- )
-
- lastfm.scrobble(
- artist=track['artist'],
- title=track['title'],
- album=track.get('album'),
- )
-```
-
-If you go for the scrobbling way, then you may want to periodically synchronize
-your scrobble history to your local database - for example, through a cron that
-runs every 30 seconds:
-
-```python
-# ~/.config/platypush/scripts/music/scrobble2db.py
-
-import logging
-
-from datetime import datetime
-
-from platypush.context import get_plugin, Variable
-from platypush.cron import cron
-
-logger = logging.getLogger('music_sync')
-music_db_engine = 'postgresql+pg8000://dbuser:dbpass@dbhost/dbname'
-
-# Use this stored variable to keep track of the time of the latest
-# synchronized scrobble
-last_timestamp_var = Variable('LAST_SCROBBLED_TIMESTAMP')
-
-
-# This cron executes every 30 seconds
-@cron('* * * * * */30')
-def sync_scrobbled_tracks(**_):
- db = get_plugin('db')
- lastfm = get_plugin('lastfm')
-
- # Use the last.fm plugin to retrieve all the new tracks scrobbled since
- # the last check
- last_timestamp = int(last_timestamp_var.get() or 0)
- tracks = [
- track for track in lastfm.get_recent_tracks().output
- if track.get('timestamp', 0) > last_timestamp
- ]
-
- # Exit if we have no new music activity
- if not tracks:
- return
-
- # Insert the new tracks on the database
- db.insert(
- engine=music_db_engine,
- table='tmp_music',
- records=[
- {
- 'artist': track.get('artist'),
- 'title': track.get('title'),
- 'album': track.get('album'),
- 'created_at': (
- datetime.fromtimestamp(track['timestamp'])
- if track.get('timestamp') else None
- ),
- }
- for track in tracks
- ]
- )
-
- # Update the LAST_SCROBBLED_TIMESTAMP variable with the timestamp of the
- # most recent played track
- last_timestamp_var.set(max(
- int(t.get('timestamp', 0))
- for t in tracks
- ))
-
- logger.info('Stored %d new scrobbled track(s)', len(tracks))
-```
-
-This cron will basically synchronize your scrobbling history to your local
-database, so we can use the local database as the source of truth for the next
-steps - no matter where the music was played from.
-
-To test the logic, simply restart Platypush, play some music from your
-favourite player(s), and check that everything gets inserted on the database -
-even if we are inserting tracks on the `tmp_music` table, the listening history
-should be automatically normalized on the appropriate tables by the triggered
-that we created at initialization time.
-
-## Updating the suggestions
-
-Now that all the plumbing to get all of your listening history in one data
-source is in place, let's move to the logic that recalculates the suggestions
-based on your listening history.
-
-We will again use the last.fm API to get tracks that are similar to those we
-listened to recently - I personally find last.fm suggestions often more
-relevant than those of Spotify's.
-
-For sake of simplicity, let's map the database tables to some SQLAlchemy ORM
-classes, so the upcoming SQL interactions can be notably simplified. The ORM
-model can be stored under e.g. `~/.config/platypush/music/db.py`:
-
-```python
-# ~/.config/platypush/scripts/music/db.py
-
-from sqlalchemy import create_engine
-from sqlalchemy.ext.automap import automap_base
-from sqlalchemy.orm import sessionmaker, scoped_session
-
-music_db_engine = 'postgresql+pg8000://dbuser:dbpass@dbhost/dbname'
-engine = create_engine(music_db_engine)
-
-Base = automap_base()
-Base.prepare(engine, reflect=True)
-Track = Base.classes.music_track
-TrackActivity = Base.classes.music_activity
-TrackSimilar = Base.classes.music_similar
-DiscoveryPlaylist = Base.classes.music_discovery_playlist
-DiscoveryPlaylistTrack = Base.classes.music_discovery_playlist_track
-NewRelease = Base.classes.new_release
-
-
-def get_db_session():
- session = scoped_session(sessionmaker(expire_on_commit=False))
- session.configure(bind=engine)
- return session()
-```
-
-Then create a new user script under e.g.
-`~/.config/platypush/scripts/music/suggestions.py` with the following content:
-
-```python
-# ~/.config/platypush/scripts/music/suggestions.py
-
-import logging
-
-from sqlalchemy import tuple_
-from sqlalchemy.dialects.postgresql import insert
-from sqlalchemy.sql.expression import bindparam
-
-from platypush.context import get_plugin, Variable
-from platypush.cron import cron
-
-from scripts.music.db import (
- get_db_session, Track, TrackActivity, TrackSimilar
-)
-
-
-logger = logging.getLogger('music_suggestions')
-
-# This stored variable will keep track of the latest activity ID for which the
-# suggestions were calculated
-last_activity_id_var = Variable('LAST_PROCESSED_ACTIVITY_ID')
-
-
-# A cronjob that runs every 5 minutes and updates the suggestions
-@cron('*/5 * * * *')
-def refresh_similar_tracks(**_):
- last_activity_id = int(last_activity_id_var.get() or 0)
-
- # Retrieve all the tracks played since the latest synchronized activity ID
- # that don't have any similar tracks being calculated yet
- with get_db_session() as session:
- recent_tracks_without_similars = \
- _get_recent_tracks_without_similars(last_activity_id)
-
- try:
- if not recent_tracks_without_similars:
- raise StopIteration(
- 'All the recent tracks have processed suggestions')
-
- # Get the last activity_id
- batch_size = 10
- last_activity_id = (
- recent_tracks_without_similars[:batch_size][-1]['activity_id'])
-
- logger.info(
- 'Processing suggestions for %d/%d tracks',
- min(batch_size, len(recent_tracks_without_similars)),
- len(recent_tracks_without_similars))
-
- # Build the track_id -> [similar_tracks] map
- similars_by_track = {
- track['track_id']: _get_similar_tracks(track['artist'], track['title'])
- for track in recent_tracks_without_similars[:batch_size]
- }
-
- # Map all the similar tracks in an (artist, title) -> info data structure
- similar_tracks_by_artist_and_title = \
- _get_similar_tracks_by_artist_and_title(similars_by_track)
-
- if not similar_tracks_by_artist_and_title:
- raise StopIteration('No new suggestions to process')
-
- # Sync all the new similar tracks to the database
- similar_tracks = \
- _sync_missing_similar_tracks(similar_tracks_by_artist_and_title)
-
- # Link listened tracks to similar tracks
- with get_db_session() as session:
- stmt = insert(TrackSimilar).values({
- 'source_track_id': bindparam('source_track_id'),
- 'target_track_id': bindparam('target_track_id'),
- 'match_score': bindparam('match_score'),
- }).on_conflict_do_nothing()
-
- session.execute(
- stmt, [
- {
- 'source_track_id': track_id,
- 'target_track_id': similar_tracks[(similar['artist'], similar['title'])].id,
- 'match_score': similar['score'],
- }
- for track_id, similars in similars_by_track.items()
- for similar in (similars or [])
- if (similar['artist'], similar['title'])
- in similar_tracks
- ]
- )
-
- session.flush()
- session.commit()
- except StopIteration as e:
- logger.info(e)
-
- last_activity_id_var.set(last_activity_id)
- logger.info('Suggestions updated')
-
-
-def _get_similar_tracks(artist, title):
- """
- Use the last.fm API to retrieve the tracks similar to a given
- artist/title pair
- """
- import pylast
- lastfm = get_plugin('lastfm')
-
- try:
- return lastfm.get_similar_tracks(
- artist=artist,
- title=title,
- limit=10,
- )
- except pylast.PyLastError as e:
- logger.warning(
- 'Could not find tracks similar to %s - %s: %s',
- artist, title, e
- )
-
-
-def _get_recent_tracks_without_similars(last_activity_id):
- """
- Get all the tracks played after a certain activity ID that don't have
- any suggestions yet.
- """
- with get_db_session() as session:
- return [
- {
- 'track_id': t[0],
- 'artist': t[1],
- 'title': t[2],
- 'activity_id': t[3],
- }
- for t in session.query(
- Track.id.label('track_id'),
- Track.artist,
- Track.title,
- TrackActivity.id.label('activity_id'),
- )
- .select_from(
- Track.__table__
- .join(
- TrackSimilar,
- Track.id == TrackSimilar.source_track_id,
- isouter=True
- )
- .join(
- TrackActivity,
- Track.id == TrackActivity.track_id
- )
- )
- .filter(
- TrackSimilar.source_track_id.is_(None),
- TrackActivity.id > last_activity_id
- )
- .order_by(TrackActivity.id)
- .all()
- ]
-
-
-def _get_similar_tracks_by_artist_and_title(similars_by_track):
- """
- Map similar tracks into an (artist, title) -> track dictionary
- """
- similar_tracks_by_artist_and_title = {}
- for similar in similars_by_track.values():
- for track in (similar or []):
- similar_tracks_by_artist_and_title[
- (track['artist'], track['title'])
- ] = track
-
- return similar_tracks_by_artist_and_title
-
-
-def _sync_missing_similar_tracks(similar_tracks_by_artist_and_title):
- """
- Flush newly calculated similar tracks to the database.
- """
- logger.info('Syncing missing similar tracks')
- with get_db_session() as session:
- stmt = insert(Track).values({
- 'artist': bindparam('artist'),
- 'title': bindparam('title'),
- }).on_conflict_do_nothing()
-
- session.execute(stmt, list(similar_tracks_by_artist_and_title.values()))
- session.flush()
- session.commit()
-
- tracks = session.query(Track).filter(
- tuple_(Track.artist, Track.title).in_(
- similar_tracks_by_artist_and_title
- )
- ).all()
-
- return {
- (track.artist, track.title): track
- for track in tracks
- }
-```
-
-Restart Platypush and let it run for a bit. The cron will operate in batches of
-10 items each (it can be easily customized), so after a few minutes your
-`music_suggestions` table should start getting populated.
-
-## Generating the discovery playlist
-
-So far we have achieved the following targets:
-
-- We have a piece of logic that synchronizes all of our listening history to a
- local database.
-- We have a way to synchronize last.fm / libre.fm scrobbles to the same
- database as well.
-- We have a cronjob that periodically scans our listening history and fetches
- the suggestions through the last.fm API.
-
-Now let's put it all together with a cron that runs every week (or daily, or at
-whatever interval we like) that does the following:
-
-- It retrieves our listening history over the specified period.
-- It retrieves the suggested tracks associated to our listening history.
-- It excludes the tracks that we've already listened to, or that have already
- been included in previous discovery playlists.
-- It generates a new discovery playlist with those tracks, ranked according to
- a simple score:
-
-$$
-\rho_i = \sum_{j \in L_i} m_{ij}
-$$
-
-Where \( \rho_i \) is the ranking of the suggested _i_-th suggested track, \(
-L_i \) is the set of listened tracks that have the _i_-th track among its
-similarities, and \( m_{ij} \) is the match score between _i_ and _j_ as
-reported by the last.fm API.
-
-Let's put all these pieces together in a cron defined in e.g.
-`~/.config/platypush/scripts/music/discovery.py`:
-
-```python
-# ~/.config/platypush/scripts/music/discovery.py
-
-import logging
-from datetime import date, timedelta
-
-from platypush.context import get_plugin
-from platypush.cron import cron
-
-from scripts.music.db import (
- get_db_session, Track, TrackActivity, TrackSimilar,
- DiscoveryPlaylist, DiscoveryPlaylistTrack
-)
-
-logger = logging.getLogger('music_discovery')
-
-
-def get_suggested_tracks(days=7, limit=25):
- """
- Retrieve the suggested tracks from the database.
-
- :param days: Look back at the listen history for the past <n> days
- (default: 7).
- :param limit: Maximum number of track in the discovery playlist
- (default: 25).
- """
- from sqlalchemy import func
-
- listened_activity = TrackActivity.__table__.alias('listened_activity')
- suggested_activity = TrackActivity.__table__.alias('suggested_activity')
-
- with get_db_session() as session:
- return [
- {
- 'track_id': t[0],
- 'artist': t[1],
- 'title': t[2],
- 'score': t[3],
- }
- for t in session.query(
- Track.id,
- func.min(Track.artist),
- func.min(Track.title),
- func.sum(TrackSimilar.match_score).label('score'),
- )
- .select_from(
- Track.__table__
- .join(
- TrackSimilar.__table__,
- Track.id == TrackSimilar.target_track_id
- )
- .join(
- listened_activity,
- listened_activity.c.track_id == TrackSimilar.source_track_id,
- )
- .join(
- suggested_activity,
- suggested_activity.c.track_id == TrackSimilar.target_track_id,
- isouter=True
- )
- .join(
- DiscoveryPlaylistTrack,
- Track.id == DiscoveryPlaylistTrack.track_id,
- isouter=True
- )
- )
- .filter(
- # The track has not been listened
- suggested_activity.c.track_id.is_(None),
- # The track has not been suggested already
- DiscoveryPlaylistTrack.track_id.is_(None),
- # Filter by recent activity
- listened_activity.c.created_at >= date.today() - timedelta(days=days)
- )
- .group_by(Track.id)
- # Sort by aggregate match score
- .order_by(func.sum(TrackSimilar.match_score).desc())
- .limit(limit)
- .all()
- ]
-
-
-def search_remote_tracks(tracks):
- """
- Search for Tidal tracks given a list of suggested tracks.
- """
- # If you use Spotify instead of Tidal, simply replacing `music.tidal`
- # with `music.spotify` here should suffice.
- tidal = get_plugin('music.tidal')
- found_tracks = []
-
- for track in tracks:
- query = track['artist'] + ' ' + track['title']
- logger.info('Searching "%s"', query)
- results = (
- tidal.search(query, type='track', limit=1).output.get('tracks', [])
- )
-
- if results:
- track['remote_track_id'] = results[0]['id']
- found_tracks.append(track)
- else:
- logger.warning('Could not find "%s" on TIDAL', query)
-
- return found_tracks
-
-
-def refresh_discover_weekly():
- # If you use Spotify instead of Tidal, simply replacing `music.tidal`
- # with `music.spotify` here should suffice.
- tidal = get_plugin('music.tidal')
-
- # Get the latest suggested tracks
- suggestions = search_remote_tracks(get_suggested_tracks())
- if not suggestions:
- logger.info('No suggestions available')
- return
-
- # Retrieve the existing discovery playlists
- # Our naming convention is that discovery playlist names start with
- # "Discover Weekly" - feel free to change it
- playlists = tidal.get_playlists().output
- discover_playlists = sorted(
- [
- pl for pl in playlists
- if pl['name'].lower().startswith('discover weekly')
- ],
- key=lambda pl: pl.get('created_at', 0)
- )
-
- # Delete all the existing discovery playlists
- # (except the latest one). We basically keep two discovery playlists at the
- # time in our collection, so you have two weeks to listen to them before they
- # get deleted. Feel free to change this logic by modifying the -1 parameter
- # with e.g. -2, -3 etc. if you want to store more discovery playlists.
- for playlist in discover_playlists[:-1]:
- logger.info('Deleting playlist "%s"', playlist['name'])
- tidal.delete_playlist(playlist['id'])
-
- # Create a new discovery playlist
- playlist_name = f'Discover Weekly [{date.today().isoformat()}]'
- pl = tidal.create_playlist(playlist_name).output
- playlist_id = pl['id']
-
- tidal.add_to_playlist(
- playlist_id,
- [t['remote_track_id'] for t in suggestions],
- )
-
- # Add the playlist to the database
- with get_db_session() as session:
- pl = DiscoveryPlaylist(name=playlist_name)
- session.add(pl)
- session.flush()
- session.commit()
-
- # Add the playlist entries to the database
- with get_db_session() as session:
- for track in suggestions:
- session.add(
- DiscoveryPlaylistTrack(
- playlist_id=pl.id,
- track_id=track['track_id'],
- )
- )
-
- session.commit()
-
- logger.info('Discover Weekly playlist updated')
-
-
-@cron('0 6 * * 1')
-def refresh_discover_weekly_cron(**_):
- """
- This cronjob runs every Monday at 6 AM.
- """
- try:
- refresh_discover_weekly()
- except Exception as e:
- logger.exception(e)
-
- # (Optional) If anything went wrong with the playlist generation, send
- # a notification over ntfy
- ntfy = get_plugin('ntfy')
- ntfy.send_message(
- topic='mirrored-notifications-topic',
- title='Discover Weekly playlist generation failed',
- message=str(e),
- priority=4,
- )
-```
-
-You can test the cronjob without having to wait for the next Monday through
-your Python interpreter:
-
-```python
->>> import os
->>>
->>> # Move to the Platypush config directory
->>> path = os.path.join(os.path.expanduser('~'), '.config', 'platypush')
->>> os.chdir(path)
->>>
->>> # Import and run the cron function
->>> from scripts.music.discovery import refresh_discover_weekly_cron
->>> refresh_discover_weekly_cron()
-```
-
-If everything went well, you should soon see a new playlist in your collection
-named _Discover Weekly [date]_. Congratulations!
-
-## Release radar playlist
-
-Another great feature of Spotify and Tidal is the ability to provide "release
-radar" playlists that contain new releases from artists that we may like.
-
-We now have a powerful way of creating such playlists ourselves though. We
-previously configured Platypush to subscribe to the RSS feed from
-newalbumreleases.net. Populating our release radar playlist involves the
-following steps:
-
-1. Creating a hook that reacts to [`NewFeedEntryEvent`
- events](https://docs.platypush.tech/platypush/events/rss.html) on this feed.
-2. The hook will store new releases that match artists in our collection on the
- `new_release` table that we created when we initialized the database.
-3. A cron will scan this table on a weekly basis, search the tracks on
- Spotify/Tidal, and populate our playlist just like we did for _Discover
- Weekly_.
-
-Let's put these pieces together in a new user script stored under e.g.
-`~/.config/platypush/scripts/music/releases.py`:
-
-```python
-# ~/.config/platypush/scripts/music/releases.py
-
-import html
-import logging
-import re
-import threading
-from datetime import date, timedelta
-from typing import Iterable, List
-
-from platypush.context import get_plugin
-from platypush.cron import cron
-from platypush.event.hook import hook
-from platypush.message.event.rss import NewFeedEntryEvent
-
-from scripts.music.db import (
- music_db_engine, get_db_session, NewRelease
-)
-
-
-create_lock = threading.RLock()
-logger = logging.getLogger(__name__)
-
-
-def _split_html_lines(content: str) -> List[str]:
- """
- Utility method used to convert and split the HTML lines reported
- by the RSS feed.
- """
- return [
- l.strip()
- for l in re.sub(
- r'(</?p[^>]*>)|(<br\s*/?>)',
- '\n',
- content
- ).split('\n') if l
- ]
-
-
-def _get_summary_field(title: str, lines: Iterable[str]) -> str | None:
- """
- Parse the fields of a new album from the feed HTML summary.
- """
- for line in lines:
- m = re.match(rf'^{title}:\s+(.*)$', line.strip(), re.IGNORECASE)
- if m:
- return html.unescape(m.group(1))
-
-
-@hook(NewFeedEntryEvent, feed_url='https://newalbumreleases.net/category/cat/feed/')
-def save_new_release(event: NewFeedEntryEvent, **_):
- """
- This hook is triggered whenever the newalbumreleases.net has new entries.
- """
- # Parse artist and album
- summary = _split_html_lines(event.summary)
- artist = _get_summary_field('artist', summary)
- album = _get_summary_field('album', summary)
- genre = _get_summary_field('style', summary)
-
- if not (artist and album):
- return
-
- # Check if we have listened to this artist at least once
- db = get_plugin('db')
- num_plays = int(
- db.select(
- engine=music_db_engine,
- query=
- '''
- select count(*)
- from music_activity a
- join music_track t
- on a.track_id = t.id
- where artist = :artist
- ''',
- data={'artist': artist},
- ).output[0].get('count', 0)
- )
-
- # If not, skip it
- if not num_plays:
- return
-
- # Insert the new release on the database
- with create_lock:
- db.insert(
- engine=music_db_engine,
- table='new_release',
- records=[{
- 'artist': artist,
- 'album': album,
- 'genre': genre,
- }],
- key_columns=('artist', 'album'),
- on_duplicate_update=True,
- )
-
-
-def get_new_releases(days=7):
- """
- Retrieve the new album releases from the database.
-
- :param days: Look at albums releases in the past <n> days
- (default: 7)
- """
- with get_db_session() as session:
- return [
- {
- 'artist': t[0],
- 'album': t[1],
- }
- for t in session.query(
- NewRelease.artist,
- NewRelease.album,
- )
- .select_from(
- NewRelease.__table__
- )
- .filter(
- # Filter by recent activity
- NewRelease.created_at >= date.today() - timedelta(days=days)
- )
- .all()
- ]
-
-
-def search_tidal_new_releases(albums):
- """
- Search for Tidal albums given a list of objects with artist and title.
- """
- tidal = get_plugin('music.tidal')
- expanded_tracks = []
-
- for album in albums:
- query = album['artist'] + ' ' + album['album']
- logger.info('Searching "%s"', query)
- results = (
- tidal.search(query, type='album', limit=1)
- .output.get('albums', [])
- )
-
- if results:
- album = results[0]
-
- # Skip search results older than a year - some new releases may
- # actually be remasters/re-releases of existing albums
- if date.today().year - album.get('year', 0) > 1:
- continue
-
- expanded_tracks += (
- tidal.get_album(results[0]['id']).
- output.get('tracks', [])
- )
- else:
- logger.warning('Could not find "%s" on TIDAL', query)
-
- return expanded_tracks
-
-
-def refresh_release_radar():
- tidal = get_plugin('music.tidal')
-
- # Get the latest releases
- tracks = search_tidal_new_releases(get_new_releases())
- if not tracks:
- logger.info('No new releases found')
- return
-
- # Retrieve the existing new releases playlists
- playlists = tidal.get_playlists().output
- new_releases_playlists = sorted(
- [
- pl for pl in playlists
- if pl['name'].lower().startswith('new releases')
- ],
- key=lambda pl: pl.get('created_at', 0)
- )
-
- # Delete all the existing new releases playlists
- # (except the latest one)
- for playlist in new_releases_playlists[:-1]:
- logger.info('Deleting playlist "%s"', playlist['name'])
- tidal.delete_playlist(playlist['id'])
-
- # Create a new releases playlist
- playlist_name = f'New Releases [{date.today().isoformat()}]'
- pl = tidal.create_playlist(playlist_name).output
- playlist_id = pl['id']
-
- tidal.add_to_playlist(
- playlist_id,
- [t['id'] for t in tracks],
- )
-
-
-@cron('0 7 * * 1')
-def refresh_release_radar_cron(**_):
- """
- This cron will execute every Monday at 7 AM.
- """
- try:
- refresh_release_radar()
- except Exception as e:
- logger.exception(e)
- get_plugin('ntfy').send_message(
- topic='mirrored-notifications-topic',
- title='Release Radar playlist generation failed',
- message=str(e),
- priority=4,
- )
-```
-
-Just like in the previous case, it's quite easy to test that it works by simply
-running `refresh_release_radar_cron` in the Python interpreter. Just like in
-the case of the discovery playlist, things will work also if you use Spotify
-instead of Tidal - just replace the `music.tidal` plugin references with
-`music.spotify`.
-
-If it all goes as expected, you will get a new playlist named _New Releases
-[date]_ every Monday with the new releases from artist that you have listened.
-
-## Conclusions
-
-Music junkies have the opportunity to discover a lot of new music today without
-ever leaving their music app. However, smart playlists provided by the major
-music cloud providers are usually implicit lock-ins, and the way they select
-the tracks that should end up in your playlists may not even be transparent, or
-even modifiable.
-
-After reading this article, you should be able to generate your discovery and
-new releases playlists, without relying on the suggestions from a specific
-music cloud. This could also make it easier to change your music provider: even
-if you decide to drop Spotify or Tidal, your music suggestions logic will
-follow you whenever you decide to go.
diff --git a/markdown/Build-your-customizable-voice-assistant-with-Platypush.md b/markdown/Build-your-customizable-voice-assistant-with-Platypush.md
index 15c68e1..a754c60 100644
--- a/markdown/Build-your-customizable-voice-assistant-with-Platypush.md
+++ b/markdown/Build-your-customizable-voice-assistant-with-Platypush.md
@@ -95,7 +95,7 @@ First things first: in order to get your assistant working you’ll need:
I’ll also assume that you have already installed Platypush on your device — the instructions are provided on
the [Github page](https://git.platypush.tech/platypush/platypush), on
-the [wiki](https://git.platypush.tech/platypush/platypush/wiki/Home#installation) and in
+the [wiki](https://git.platypush.tech/platypush/platypush/-/wikis/home#installation) and in
my [previous article](https://blog.platypush.tech/article/Ultimate-self-hosted-automation-with-Platypush).
Follow these steps to get the assistant running:
diff --git a/markdown/Building-a-better-digital-reading-experience.md b/markdown/Building-a-better-digital-reading-experience.md
deleted file mode 100644
index 2a414b0..0000000
--- a/markdown/Building-a-better-digital-reading-experience.md
+++ /dev/null
@@ -1,786 +0,0 @@
-[//]: # (title: Building a better digital reading experience)
-[//]: # (description: Bypass client-side restrictions on news and blog articles, archive them and read them on any offline reader)
-[//]: # (image: https://s3.platypush.tech/static/images/reading-experience.jpg)
-[//]: # (author: Fabio Manganiello <fabio@manganiello.tech>)
-[//]: # (published: 2025-06-05)
-
-I've always been an avid book reader as a kid.
-
-I liked the smell of the paper, the feeling of turning the pages, and the
-ability to read them anywhere I wanted, as well as lend them to friends and
-later share our reading experiences.
-
-As I grew and chose a career in tech and a digital-savvy lifestyle, I started
-to shift my consumption from the paper to the screen. But I *still* wanted the
-same feeling of a paper book, the same freedom of reading wherever I wanted
-without distractions, and without being constantly watched by someone who will
-recommend me other products based on what I read or how I read.
-
-I was an early support of the Amazon Kindle idea. I quickly moved most of my
-physical books to the Kindle, I became a vocal supporter of online magazines
-that also provided Kindle subscriptions, and I started to read more and more on
-e-ink devices.
-
-Then I noticed that, after an initial spike, not many magazines and blogs
-provided Kindle subscriptions or EPub versions of their articles.
-
-So nevermind - I started tinkering my way out of it and [wrote an article in
-2019](https://blog.platypush.tech/article/Deliver-articles-to-your-favourite-e-reader-using-Platypush)
-on how to use [Platypush](https://platypush.tech) with its
-[`rss`](https://docs.platypush.tech/platypush/plugins/rss.html),
-[`instapaper`](https://docs.platypush.tech/platypush/plugins/instapaper.html) and
-[`gmail`](https://docs.platypush.tech/platypush/plugins/google.mail.html)
-plugins to subscribe to RSS feeds, parse new articles, convert them to PDF and
-deliver them to my Kindle.
-
-Later I moved from Kindle to the first version of the
-[Mobiscribe](https://www.mobiscribe.com), as Amazon started to be more and more
-restrictive in its option to import and export stuff out of the Kindle. Using
-Calibre and some DRM removal tools to export articles or books I had regularly
-purchased was gradually getting more cumbersome and error-prone, and the
-Mobiscribe at that time was an interesting option because it offered a decent
-e-ink device, for a decent price, and it ran Android (an ancient version, but
-at least one that was sufficient to run [Instapaper](https://instapaper.com)
-and [KOReader](https://koreader.rocks)).
-
-That simplified things a bit because I didn't need intermediary delivery via
-email to get stuff on my Kindle or Calibre to try and pull things out of it. I
-was using Instapaper on all of my devices, included the Mobiscribe, I could
-easily scrape and push articles to it through Platypush, and I could easily
-keep track of my reading state across multiple devices.
-
-Good things aren't supposed to last though.
-
-Instapaper started to feel quite limited in its capabilities, and I didn't like
-the idea of a centralized server holding all of my saved articles. So I've
-moved to a self-hosted [Wallabag](https://wallabag.org) instance in the
-meantime - which isn't perfect, but provides a lot more customization and
-control.
-
-Moreover, more and more sites started implementing client-side restrictions for
-my scrapers - Instapaper was initially more affected, as it was much easier for
-publisher's websites to detect scraping requests coming from the same subnet,
-but slowly Wallabag too started bumping into Cloudflare screens, CAPTCHAs and
-paywalls.
-
-So the Internet Archive provided some temporary relief - I could still archive
-articles there, and then instruct my Wallabag instance to read them from the
-archived link.
-
-Except that, in the past few months, the Internet Archive has also started
-implementing anti-scraping features, and you'll most likely get a Cloudflare
-screen if you try and access an article from an external scraper.
-
-## An ethical note before continuing
-
-_Feel free to skip this part and go to the technical setup section if you
-already agree that, if buying isn't owning, then piracy isn't stealing._
-
-#### Support your creators (even when you wear your pirate hat)
-
-I _do not_ condone nor support piracy when it harms content creators.
-
-Being a content creator myself I know how hard it is to squeeze some pennies
-out of our professions or hobbies, especially in a world like the digital
-one where there are often too many intermediaries to take a share of the pie.
-
-I don't mind however harming any intermediaries that add friction to the
-process just to have a piece of the pie, stubbornly rely on unsustainable
-business models that sacrifices both the revenue of the authors and the privacy
-and freedom of the readers, and prevent me from having a raw file that I can
-download and read wherever I want just I would do with a physical book or
-magazine. It's because of those folks that the digital reading experience,
-despite all the initial promises, has become much worse than the analog one.
-So I don't see a big moral conundrum in pirating to harm those folks and get
-back my basic freedoms as a reader.
-
-But I do support creators via Patreon. I pay for subscriptions to digital
-magazines that I will anyway never read through their official app. Every now
-and then I buy physical books and magazines that I've already read and that
-I've really enjoyed, to support the authors, just like I still buy some vinyls
-of albums I really love even though I could just stream them. And I send
-one-off donations when I find that some content was particularly useful to me.
-And I'd probably support content creators even more if only more of their
-distribution channels allowed me to pay only for the digital content that I
-want to consume, if only there was a viable digital business model also for the
-occasional reader, instead of everybody trying to lock me into a Hotel
-California subscription ("_you can check out any time you like, but you can
-never leave_") just because their business managers are those folks who have
-learned how to use the hammer of the recurring revenue, and think that every
-problem in the world is a subscription nail to be hit on its head. Maybe
-micropayments could be a solution, but for now cryptobros have decided that the
-future of modern digital payments should be more like a gambling den for thugs,
-shitcoin speculators and miners, rather than a solution to directly put in
-contact content creators and consumers, bypassing all the intermediaries, and
-let consumers pay only for what they consume.
-
-#### The knowledge distribution problem
-
-I also believe that the most popular business model behind most of the
-high-quality content available online (locking people into apps and
-subscriptions in order to view the content) is detrimental for the distribution
-of knowledge in what's supposed to be the age of information. If I want to be
-exposed to diverse opinions on what's going on in different industries or
-different parts of the world, I'd probably need at least a dozen subscriptions
-and a similar number of apps on my phone, all pushing notifications, while in
-earlier generations folks could just walk into their local library or buy a
-single book or a single issue of a newspaper every now and then.
-
-I don't think that we should settle for a world where the best reports, the
-best journalism and the most insightful blog articles are locked behind
-paywalls, subscriptions and closed apps, without even a Spotify/Netflix-like
-all-you-can-eat solution being considered to lower access barriers, and all
-that's left for free is cheap disinformation on social media and AI-generated
-content. Future historians will have a very hard time deciphering what was
-going on in the world in the 2020s, because most of the high-quality content
-needed to decipher our age is locked behind some kind of technological wall.
-The companies that run those sites and build those apps will most likely be
-gone in a few years or decades. And, if publishers also keep waging war against
-folks like the Internet Archive, then future historians may really start
-looking at our age like some kind of strange hyper-connected digital dark age.
-
-#### The content consumption problem
-
-I also think that it's my right, as a reader, to be able to consume content on
-a medium without distractions - like social media buttons, ads, comments, or
-other stuff that distracts me from the main content. And, if the publisher
-doesn't provide me with a solution for that, and I have already paid for the
-content, then I should be granted the right to build such a solution myself.
-Even in an age where attention is the new currency, at least we should not try
-to grab people's attention when they're trying to read some dense content. Just
-like you wouldn't interrupt someone who's reading in a library saying "hey btw,
-I know a shop that sells exactly the kind of tea cups described in the page
-you're reading right now".
-
-And I also demand the right to access the content I've paid however I want.
-
-Do I want to export everything to Markdown or read it in ASCII art in a
-terminal? Do I want to export it to EPUB so I can read it on my e-ink device?
-Do I want to export it to PDF and email it to one of my colleagues for a research
-project, or to myself for later reference? Do I want to access it without
-having to use their tracker-ridden mobile app, or without being forced to see
-ads despite having paid for a subscription? Well, that's my business. I firmly
-believe that it's not an author's or publisher's right to dictate how I access
-the content after paying for it. Just like in earlier days nobody minded if,
-after purchasing a book, I would share it with my kids, or lend it to a friend,
-or scan it and read it on my computer, or make the copies of a few pages to
-bring to my students or my colleagues for a project, or leave it on a bench at
-the park or in a public bookshelf after reading it.
-
-If some freedoms were legally granted to me before, and now they've been taken
-away, then it's not piracy if I keep demanding those freedoms. The whole point
-of a market-based economy should be to keep the customer happy and give more
-choice and freedom, not less, as technology advances. Otherwise the market is
-probably not working as intended.
-
-#### The content ownership problem
-
-Content ownership is another issue in the current digital media economy.
-
-I'll probably no longer be able to access content I've read during my
-subscription period once my subscription expires, especially if it was only
-available through an app. In the past I could cancel my subscription to
-National Geographic at any moment, and all the copies I had purchased wouldn't
-just magically disappear from my bookshelf after paying the last bill.
-
-I'll not be able to pass on the books or magazines I've read in my lifetime to
-my kid. I'll never be able to lend them to someone else, just like I would leave
-a book I had read on a public bookshelf or a bench at the park for someone else
-to read it.
-
-In other words, buying now grants you a temporary license to access the content
-on someone else's device - you don't really own anything.
-
-So, if buying isn't owning, piracy isn't stealing.
-
-And again, to make it very clear, I'll be referring to *personal use* in this
-article. The case where you support creators through other means, but the
-distribution channel and the business models are the problem, and you just
-want your basic freedoms as a content consumer back.
-
-If however you want to share scraped articles on the Web, or even worse profit
-from access to it without sharing those profits with the creators, then you're
-*really* doing the kind of piracy I can't condone.
-
-With this out of the way, let's get our hands dirty.
-
-## The setup
-
-A high-level overview of the setup is as follows:
-
-<img alt="High-level overview of the scraper setup" src="https://s3.platypush.tech/static/images/wallabag-scraper-architecture.png" width="650px">
-
-Let's break down the building blocks of this setup:
-
-- **[Redirector](https://addons.mozilla.org/en-US/firefox/addon/redirector/)**
- is a browser extension that allows you to redirect URLs based on custom
- rules as soon as the page is loaded. This is useful to redirect paywalled
- resources to the Internet Archive, which usually stores full copies of the
- content. Even if you regularly paid for a subscription to a magazine, and you
- can read the article on the publisher's site or from their app, your Wallabag
- scraper will still be blocked if the site implements client-side restrictions
- or is protected by Cloudflare. So you need to redirect the URL to the Internet
- Archive, which will then return a copy of the article that you can scrape.
-
-- **[Platypush](https://platypush.tech)** is a Python-based general-purpose
- platform for automation that I've devoted a good chunk of the past decade
- to develop. It allows you to run actions, react to events and control devices
- and services through a unified API and Web interface, and it comes with
- [hundreds of supported integrations](https://docs.platypush.tech). We'll use
- the [`wallabag`](https://docs.platypush.tech/platypush/plugins/wallabag.html)
- plugin to push articles to your Wallabag instance, and optionally the
- [`rss`](https://docs.platypush.tech/platypush/plugins/rss.html) plugin if you
- want to programmatically subscribe to RSS feeds, scrape articles and archive
- them to Wallabag, and the
- [`ntfy`](https://docs.platypush.tech/platypush/plugins/ntfy.html) plugin to
- optionally send notifications to your mobile device when new articles are
- available.
-
-- **[Platypush Web extension](https://addons.mozilla.org/en-US/firefox/addon/platypush/)**
- is a browser extension that allows you to interact with Platypush from your
- browser, and it also provides a powerful JavaScript API that you can leverage
- to manipulate the DOM and automate tasks in the browser. It's like a
- [Greasemonkey](https://addons.mozilla.org/en-US/firefox/addon/greasemonkey/)
- or [Tampermonkey](https://addons.mozilla.org/en-US/firefox/addon/tampermonkey/)
- extension that allows you to write scripts to customize your browser
- experience, but it also allows you to interact with Platypush and leverage
- its backend capabilities. On top of that, I've also added built-in support
- for the [Mercury Parser API](https://github.com/usr42/mercury-parser) in it,
- so you can easily distill articles - similar to what Firefox does with its
- [Reader
- Mode](https://support.mozilla.org/en-US/kb/firefox-reader-view-clutter-free-web-pages),
- but in this case you can customize the layout and modify the original DOM
- directly, and the distilled content can easily be dispatched to any other
- service or application. We'll use it to:
-
- - Distill the article content from the page, removing all the
- unnecessary elements (ads, comments, etc.) and leaving only the main text
- and images.
-
- - Archive the distilled article to Wallabag, so you can read it later
- from any device that has access to your Wallabag instance.
-
-- **[Wallabag](https://wallabag.org)** is a self-hosted read-it-later
- service that allows you to save articles from the Web and read them later,
- even offline. It resembles the features of the ([recently
- defunct](https://support.mozilla.org/en-US/kb/future-of-pocket))
- [Pocket](https://getpocket.com/home). It provides a Web interface, mobile
- apps and browser extensions to access your saved articles, and it can also be
- used as a backend for scraping articles from the Web.
-
-- (_Optional_) **[KOReader](https://koreader.rocks)** is an
- open-source e-book reader that runs on a variety of devices, including any
- e-ink readers that run Android (and even the
- [Remarkable](https://github.com/koreader/koreader/wiki/Installation-on-Remarkable)).
- It has a quite minimal interface and it may take a while to get used to, but
- it's extremely powerful and customizable. I personally prefer it over the
- official Wallabag app - it has a native Wallabag integration, as well as OPDS
- integration to synchronize with my
- [Ubooquity](https://docs.linuxserver.io/images/docker-ubooquity/) server,
- synchronization of highlights and notes to Nextcloud Notes, WebDAV support
- (so you can access anything hosted on e.g. your Nextcloud instance), progress
- sync across devices through their [sync
- server](https://github.com/koreader/koreader-sync-server), and much more. It
- basically gives you a single app to access your saved articles, your books,
- your notes, your highlights, and your documents.
-
-- (_Optional_) An Android-based e-book reader to run KOReader on. I have
- recently switched from my old Mobiscribe to an [Onyx BOOX Note Air
- 4](https://www.onyxbooxusa.com/onyx-boox-note-air4-c) and I love it. It's
- powerful, the display is great, it runs basically any Android app out there
- (and I've had no issues with running any apps installed through
- [F-Droid](https://f-droid.org)), and it also has a good set of stock apps,
- and most of them support WebDAV synchronization - ideal if you have a
- [Nextcloud](https://nextcloud.com) instance to store your documents and
- archived links.
-
-**NOTE**: The Platypush extension only works with Firefox, on any Firefox-based
-browser, or on any browser out there that still supports the [Manifest
-V2](https://blog.mozilla.org/addons/2024/03/13/manifest-v3-manifest-v2-march-2024-update/).
-The Manifest V3 has been a disgrace that Google has forced all browser
-extension developers to swallow. I won't go in detail here, but the Platypush
-extension needs to be able to perform actions (such as calls to custom remote
-endpoints and runtime interception of HTTP headers) that are either no longer
-supported on Manifest V3, or that are only supported through laborious
-workarounds (such as using the declarative Net Request API to explicitly
-define what you want to intercept and what remote endpoints you want to call).
-
-**NOTE 2**: As of June 2025, the Platypush extension is only supported on
-Firefox for desktop. A Firefox for Android version [is
-work in progress](https://git.platypush.tech/platypush/platypush-webext/issues/1).
-
-Let's dig deeper into the individual components of this setup.
-
-## Redirector
-
-
-
-This is a nice addition if you want to automatically view some links through
-the Internet Archive rather than the original site.
-
-You can install it from the [Firefox Add-ons site](https://addons.mozilla.org/en-US/firefox/addon/redirector/).
-Once installed, you can create a bunch of rules (regular expressions are supported)
-to redirect URLs from paywalled domains that you visit often to the Internet Archive.
-
-For example, this regular expression:
-
-```
-^(https://([\w-]+).substack.com/p/.*)
-```
-
-will match any Substack article URL, and you can redirect it to the Internet Archive
-through this URL:
-
-```
-https://archive.is/$1
-```
-
-Next time you open a Substack article, it will be automatically redirected to its
-most recent archived version - or it will prompt you to archive the URL if it's not
-been archived yet.
-
-## Wallabag
-
-
-
-Wallabag can easily be installed on any server [through Docker](https://doc.wallabag.org/developer/docker/).
-
-Follow the documentation for the set up of your user and create an API token
-from the Web interface.
-
-It's also advised to [set up a reverse
-proxy](https://doc.wallabag.org/admin/installation/virtualhosts/#configuration-on-nginx)
-in front of Wallabag, so you can easily access it over HTTPS.
-
-Once configured the reverse proxy, you can generate a certificate for it - for
-example, if you use [`certbot`](https://certbot.eff.org/) and `nginx`:
-
-```bash
-❯ certbot --nginx -d your-domain.com
-```
-
-Then you can access your Wallabag instance at `https://your-domain.com` and log
-in with the user you created.
-
-Bonus: I personally find the Web interface of Wallabag quite ugly - the
-fluorescent light blue headers are distracting and the default font and column
-width isn't ideal for my taste. So I made a [Greasemonkey/Tampermonkey
-script](https://gist.manganiello.tech/fabio/ec9e28170988441d9a091b3fa6535038)
-to make it better if you want (see screenshot above).
-
-## [_Optional_] ntfy
-
-[ntfy](https://ntfy.sh) is a simple HTTP-based pub/sub notification service
-that you can use to send notifications to your devices or your browser. It
-provides both an [Android app](https://f-droid.org/en/packages/io.heckel.ntfy/)
-and a [browser
-addon](https://addons.mozilla.org/en-US/firefox/addon/send-to-ntfy/) to send
-and receive notifications, allowing you to open saved links directly on your
-phone or any other device subscribed to the same topic.
-
-Running it via docker-compose [is quite
-straightforward](https://github.com/binwiederhier/ntfy/blob/main/docker-compose.yml).
-
-It's also advised to serve it behind a reverse proxy with HTTPS support,
-keeping in mind to set the right header for the Websocket paths - example nginx
-configuration:
-
-```nginx
-map $http_upgrade $connection_upgrade {
- default upgrade;
- '' close;
-}
-
-server {
- server_name notify.example.com;
-
- location / {
- proxy_pass http://your-internal-ntfy-host:port;
-
- client_max_body_size 5M;
-
- proxy_read_timeout 60;
- proxy_connect_timeout 60;
- proxy_redirect off;
-
- proxy_set_header Host $http_host;
- proxy_set_header X-Real-IP $remote_addr;
- proxy_set_header X-Forwarded-Ssl on;
- proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
- }
-
- location ~ .*/ws/?$ {
- proxy_http_version 1.1;
- proxy_set_header Upgrade $http_upgrade;
- proxy_set_header Connection $connection_upgrade;
- proxy_set_header Host $http_host;
- proxy_pass http://your-internal-ntfy-host:port;
- }
-}
-```
-
-Once the server is running, you can check the connectivity by opening your
-server's main page in your browser.
-
-**NOTE**: Be _careful_ when choosing your ntfy topic name, especially if you
-are using a public instance. ntfy by default doesn't require any authentication
-for publishing or subscribing to a topic. So choose a random name (or at least
-a random prefix/suffix) for your topics and treat them like a password.
-
-## Platypush
-
-Create a new virtual environment and install Platypush through `pip` (the
-plugins we'll use in the first part don't require any additional dependencies):
-
-```bash
-❯ python3 -m venv venv
-❯ source venv/bin/activate
-❯ pip install platypush
-```
-
-Then create a new configuration file `~/.config/platypush/config.yaml` with the
-following configuration:
-
-```yaml
-# Web server configuration
-backend.http:
- # port: 8008
-
-# Wallabag configuration
-wallabag:
- server_url: https://your-domain.com
- client_id: your_client_id
- client_secret: your_client_secret
- # Your Wallabag user credentials are required for the first login.
- # It's also advised to keep them here afterwards so the refresh
- # token can be automatically updated.
- username: your_username
- password: your_password
-```
-
-Then you can start the service with:
-
-```bash
-❯ platypush
-```
-
-You can also create a systemd service to run Platypush in the background:
-
-```bash
-❯ mkdir -p ~/.config/systemd/user
-❯ cat <<EOF > ~/.config/systemd/user/platypush.service
-[Unit]
-Description=Platypush service
-After=network.target
-
-[Service]
-ExecStart=/path/to/venv/bin/platypush
-Restart=always
-RestartSec=5
-EOF
-❯ systemctl --user daemon-reload
-❯ systemctl --user enable --now platypush.service
-```
-
-After starting the service, head over to `http://your_platypush_host:8008` (or
-the port you configured in the `backend.http` section) and create a new user
-account.
-
-It's also advised to serve the Platypush Web server behind a reverse proxy with
-HTTPS support if you want it to easily be accessible from the browser extension -
-a basic `nginx` configuration [is available on the
-repo](https://git.platypush.tech/platypush/platypush/src/branch/master/examples/nginx/nginx.sample.conf).
-
-## Platypush Web extension
-
-You can install the Platypush Web extension from the [Firefox Add-ons
-site](https://addons.mozilla.org/en-US/firefox/addon/platypush/).
-
-After installing it, click on the extension popup and add the URL of your
-Platypush Web server.
-
-
-
-When successfully connected, you should see the device in the main menu, you
-can run commands on it and save actions.
-
-A good place to start familiarizing with the Platypush API is the _Run Action_
-dialog, which allows you to run commands on your server and provides
-autocomplete for the available actions, as well as documentation about their
-arguments.
-
-
-
-The default action mode is _Request_ (i.e. single requests against the API).
-You can also pack together more actions on the backend [into
-_procedures_](https://docs.platypush.tech/wiki/Quickstart.html#greet-me-with-lights-and-music-when-i-come-home),
-which can be written either in the YAML config or as Python scripts (by default
-loaded from `~/.config/platypush/scripts`). If correctly configured, procedures
-will be available in the _Run Action_ dialog.
-
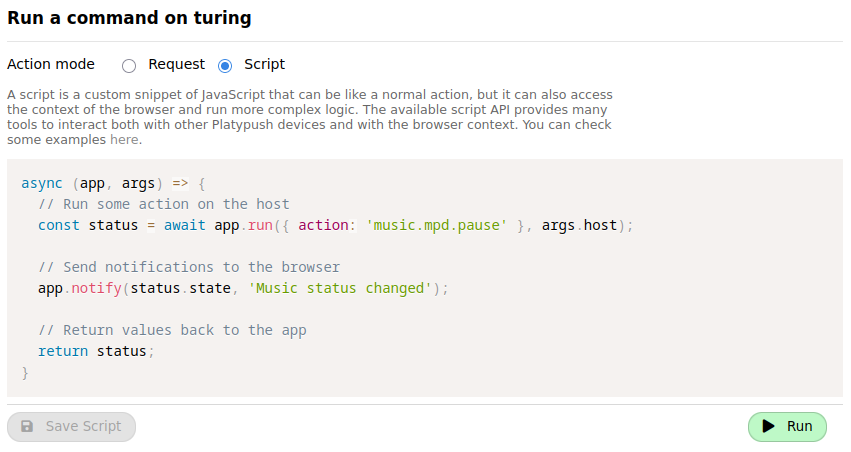
-The other mode, which we'll use in this article, is _Script_. In this mode you
-can write custom JavaScript code that can interact with your browser.
-
-
-
-[Here](https://gist.github.com/BlackLight/d80c571705215924abc06a80994fd5f4) is
-a sample script that you can use as a reference for the API exposed by the
-extension. Some examples include:
-
-- `app.run`, to run an action on the Platypush backend
-
-- `app.getURL`, `app.setURL` and `app.openTab` to get and set the current URL,
- or open a new tab with a given URL
-
-- `app.axios.get`, `app.axios.post` etc. to perform HTTP requests to other
- external services through the Axios library
-
-- `app.getDOM` and `app.setDOM` to get and set the current page DOM
-
-- `app.mercury.parse` to distill the current page content using the Mercury
- Parser API
-
-### Reader Mode script
-
-We can put together the building blocks above to create our first script, which
-will distill the current page content and swap the current page DOM with the
-simplified content - with no ads, comments, or other distracting visual
-elements. The full content of the script is available
-[here](https://gist.manganiello.tech/fabio/c731b57ff6b24d21a8f43fbedde3dc30).
-
-This is akin to what Firefox' [Reader
-Mode](https://support.mozilla.org/en-US/kb/firefox-reader-view-clutter-free-web-pages)
-does, but with much more room for customization.
-
-Note that for this specific script we don't need any interactions with the
-Platypush backend. Everything happens on the client, as the Mercury API is
-built into the Platypush Web extension.
-
-Switch to _Script_ mode in the _Run Action_ dialog, paste the script content
-and click on _Save Script_. You can also choose a custom name, icon
-([FontAwesome](https://fontawesome.com/icons) icon classes are supported),
-color and group for the script. Quite importantly, you can also associate a
-keyboard shortcut to it, so you can quickly distill a page without having to
-search for the command either in the extension popup or in the context menu.
-
-### Save to Wallabag script
-
-Now that we have a script to distill the current page content, we can create
-another script to save the distilled content (if available) to Wallabag.
-Otherwise, it will just save the original page content.
-
-The full content of the script is available
-[here](https://gist.manganiello.tech/fabio/8f5b08d8fbaa404bafc6fdeaf9b154b4).
-The structure is quite straightforward:
-
-- First, it checks if the page content has already been "distilled" by the
- Reader Mode script. If so, it uses the distilled content to save it to
- Wallabag. Otherwise, it will use the full page body.
-
-- It saves the URL to Wallabag.
-
-- Optionally, it sends a notification over ntfy.
-
-Again, feel free to assign a keybinding to this action so you can quickly call
-it from any page.
-
-Personally I've picked `Ctrl+Alt+1` for the Reader Mode script and `Ctrl+Alt+2`
-for the Save to Wallabag script, so I can quickly distill a page and, if takes
-me more time to read it, send the already simplified content to Wallabag.
-
-If you don't want to create a keybinding, you can always call these actions
-either from the extension popup or from the (right click) context menu.
-
-## [_Optional_] RSS subscriptions and automated delivery
-
-You now have a way to manually scrape and archive articles from the Web.
-
-If you are also a regular reader of a publication or a blog that provides RSS
-or Atom feeds, you can also automate the process of subscribing to those feeds
-and delivering new articles to Wallabag.
-
-Just keep in mind two things if you want to go down this way:
-
-1. It's not advised to subscribe to feeds that provide a lot of articles
- every day, as this will quickly fill up your Wallabag instance and make it
- hard to find the articles you want to read. So stick to feeds that provide
- one or a few articles per day, or at least don't provide more than a dozen
- articles per day. Or augment the RSS event hook with custom filters to only
- include links that match some criteria.
-
-2. Unlike the manual actions we saw before, the logic to handle automated
- subscriptions and content delivery is implemented on the Platypush service
- (on the backend). So it may not be as optimal in scraping and distilling
- articles as some logic that operates on the client side and can more easily
- bypass client-side restrictions. So you may want to pick feeds that don't
- implement aggressive paywalls, are behind Cloudflare, or implement other
- client-side restrictions.
-
-If you have some good candidates for automated delivery, follow these steps:
-
-- Install the [`rss`](https://docs.platypush.tech/platypush/plugins/rss.html)
- plugin in your Platypush instance:
-
-```bash
-(venv)> pip install 'platypush[rss]'
-```
-
-- If you want to use the Mercury Parser API to distill articles (_optional_),
- install the dependencies for the
- [`http.webpage`](https://docs.platypush.tech/platypush/plugins/http.webpage.html).
- The Mercury API is only available in JavaScript, so you'll need to have
- `nodejs` and `npm` installed on your system. The Mercury Parser API is optional,
- but it's usually more successful than the default Wallabag scraper in distilling
- content. And, on top of that, it also makes it easier to customize your
- requests. So if you want to scrape content from paywalled websites that
- you're subscribed to you can easily pass your credentials or cookies to the
- Mercury API (Wallabag doesn't support customizing the scraping requests).
- Moreover, the Mercury integration also allows you to export the distilled
- content to other formats, such as plain text, HTML, Markdown, or PDF - this
- is useful if you want to save content to other services or applications. For
- example, I find it quite useful to scrape content from some articles in
- Markdown, and then save it to my [Nextcloud
- Notes](https://apps.nextcloud.com/apps/notes) or
- [Obsidian](https://obsidian.md).
-
-```bash
-# Example for Debian/Ubuntu
-❯ [sudo] apt install nodejs npm
-# Install Mercury Parser globally
-❯ [sudo] npm install -g @postlight/parser
-```
-
-- Add your subscriptions to the `~/.config/platypush/config.yaml` file:
-
-```yaml
-rss:
- subscriptions:
- - https://example.com/feed.xml
- - https://example.com/atom.xml
-
-# Optional
-# http.webpage
-# headers:
-# # These headers will be used in all the requests made by the Mercury Parser.
-# # You can still override the headers when you call the `http.webpage.simplify`
-# # action though.
-# User-Agent: "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
-```
-
-- Create an event hook to handle new articles from the RSS feed and
- distill them using the Mercury Parser API. You can e.g. create a
- `~/.config/platypush/scripts/subscriptions.py` file with the following
- content:
-
-```python
-import logging
-import urllib.parse
-
-from platypush import run, when
-from platypush.events.rss import NewFeedEntryEvent
-
-logger = logging.getLogger(__name__)
-
-# Optional, set the False if you don't want to use the Mercury Parser API
-USE_MERCURY_PARSER = True
-
-# If there are any websites that require specific headers to be passed,
-# for example paywalled news sites that you're subscribed to and require
-# authentication, you can specify them here.
-headers_by_domain = {
- 'example.com': {
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
- 'Accept-Language': 'en-US,en;q=0.5',
- 'Cookie': 'sessionid=your_cookie_value; other_cookie=other_value',
- },
-}
-
-
-def get_headers(url: str) -> dict:
- """
- Get the headers to use for the request based on the URL.
- """
- domain = re.sub(r'^www\.', '', urllib.parse.urlparse(url).netloc)
- return headers_by_domain.get(domain, {})
-
-
-@when(NewFeedEntryEvent)
-def scrape_and_save(event: NewFeedEntryEvent, **_):
- """
- Scrape and save the new article to Wallabag.
- """
- content = None
- logger.info(
- 'New article available on %s - title: %s, url: %s',
- event.feed_url,
- event.title,
- event.url
- )
-
- if USE_MERCURY_PARSER:
- # Distill the article content using the Mercury Parser API
- response = run(
- 'http.webpage.simplify',
- url=url,
- format='html',
- headers=get_headers(event.url),
- )
-
- if not (response and response.get('content')):
- logger.warning(f'Failed to distill {url} through Mercury Parser')
- else:
- content = response['content']
-
- # Save the distilled content to Wallabag
- run(
- 'wallabag.save',
- title=event.entry.title,
- content=content,
- url=url,
- )
-
- logger.info(f'Saved {url} to Wallabag')
-```
-
-It is advised to run the Platypush script once _without_ the `@when` hook
-above, but with the `rss` plugin configured.
-
-The reason is that, on the first run, the `rss` plugin will fetch all the
-entries in the subscribed feeds and trigger the `NewFeedEntryEvent` for each
-of them. That in turn could end up with hundreds of articles pushed
-simultaneously to your Wallabag instance, you may not want that.
-
-The recommended flow instead (which should probably apply also any time you add
-new feeds to your subscriptions) is:
-
-1. Add the feeds to your `rss` plugin configuration.
-
-2. Restart the Platypush service and let it process all the `NewFeedEntryEvent`
- events for the existing articles.
-
-3. Add the event hook logic to any file under `~/.config/platypush/scripts`.
-
-4. Restart the service - now only new entries will trigger the events.
-
-## Conclusions
-
-In this article we have seen how to set up a self-hosted solution to scrape and
-archive articles from the Web, and also how to automate the process through
-feed subscriptions.
-
-This is a powerful way to regain control over your reading experience, hopefully
-bringing it one step closer to the one you had with paper books or walks to the
-local library.
-
-Just remember to do so responsibly, only for personal use, and respecting the
-rights of content creators and publishers.
-
-It's fine to get creative and build your own reading experience by bypassing
-all the needless friction that has been added as media has moved to the digital
-space.
-
-But always remember to fund authors and creators in other ways, subscribe to
-those who produce high-quality content (even if you don't read content from
-their mobile app), and try to limit your scraping experience to personal use.
diff --git a/markdown/Create-a-Mastodon-bot-to-forward-Twitter-and-RSS-feeds-to-your-timeline.md b/markdown/Create-a-Mastodon-bot-to-forward-Twitter-and-RSS-feeds-to-your-timeline.md
index e3724d4..0907541 100644
--- a/markdown/Create-a-Mastodon-bot-to-forward-Twitter-and-RSS-feeds-to-your-timeline.md
+++ b/markdown/Create-a-Mastodon-bot-to-forward-Twitter-and-RSS-feeds-to-your-timeline.md
@@ -325,10 +325,10 @@ can run a UNIX-like system and it has HTTP access to the instance that hosts
your bot.
Install Python 3 and `pip` if they aren't installed already. Then install
-Platypush with the `rss` integration:
+Platypush with the `rss` and `mastodon` integrations:
```bash
-[sudo] pip3 install 'platypush[rss]'
+[sudo] pip3 install 'platypush[rss,mastodon]'
```
Now create a configuration file under `~/.config/platypush/config.yaml` that
@@ -359,12 +359,6 @@ Fortunately, the admins of `nitter.net` still do a good job in bridging Twitter
timelines to RSS feeds, so in `rss.subscriptions` we use `nitter.net` URLs as a
proxy to Twitter timelines.
-> UPDATE: `nitter.net` has got a lot of traffic lately, especially after the
-> recent events at Twitter. So keep in mind that the main instance may not
-> always be accessible. You can consider using other nitter instances, or, even
-> better, run one yourself (Nitter is open-source and light enough to run on a
-> Raspberry Pi).
-
Now create a script under `~/.config/platypush/scripts` named e.g.
`mastodon_bot.py`. Its content can be something like the following:
diff --git a/markdown/Detect-people-with-a-RaspberryPi-a-thermal-camera-Platypush-and-a-pinch-of-machine-learning.md b/markdown/Detect-people-with-a-RaspberryPi-a-thermal-camera-Platypush-and-a-pinch-of-machine-learning.md
index d81a3a2..7c0cef2 100644
--- a/markdown/Detect-people-with-a-RaspberryPi-a-thermal-camera-Platypush-and-a-pinch-of-machine-learning.md
+++ b/markdown/Detect-people-with-a-RaspberryPi-a-thermal-camera-Platypush-and-a-pinch-of-machine-learning.md
@@ -95,8 +95,8 @@ camera module.
This post assumes that you have already installed and configured Platypush on your system. If not, head to my post on
[getting started with Platypush](https://blog.platypush.tech/article/Ultimate-self-hosted-automation-with-Platypush),
the [readthedocs page](https://docs.platypush.tech/en/latest/), the
-[repository page](https://git.platypush.tech/platypush/platypush) or
-[the wiki](https://git.platypush.tech/platypush/platypush/wiki).
+[Gitlab page](https://git.platypush.tech/platypush/platypush) or
+[the wiki](https://git.platypush.tech/platypush/platypush/-/wikis/home).
Install also the Python dependencies for the HTTP server, the MLX90640 plugin and Tensorflow:
diff --git a/markdown/One-browser-extension-to-rule-them-all.md b/markdown/One-browser-extension-to-rule-them-all.md
index 308e3b8..53b3ca9 100644
--- a/markdown/One-browser-extension-to-rule-them-all.md
+++ b/markdown/One-browser-extension-to-rule-them-all.md
@@ -475,7 +475,7 @@ no cloud!), or loaded from a URL.
## Work in Progress
The extension is still under development, and I’m open to suggestions, tickets, and pull requests on the
-[repository page](https://git.platypush.tech/platypush/platypush-webext). Two features, in particular, are next on my
+[Gitlab page](https://git.platypush.tech/platypush/platypush-webext). Two features, in particular, are next on my
roadmap:
### Integration with the Platypush WebSocket protocol
diff --git a/markdown/Platypush-1.0-is-out.md b/markdown/Platypush-1.0-is-out.md
deleted file mode 100644
index bab5080..0000000
--- a/markdown/Platypush-1.0-is-out.md
+++ /dev/null
@@ -1,268 +0,0 @@
-[//]: # (title: Platypush 1.0 is out)
-[//]: # (description: It's software maturity time)
-[//]: # (image: https://platypush-static.s3.nl-ams.scw.cloud/images/release-1.0.png)
-[//]: # (author: Fabio Manganiello <fabio@platypush.tech>)
-[//]: # (published: 2024-05-26)
-
-It's been [10 months](https://pypi.org/project/platypush/#history) and [1049
-commits](https://git.platypush.tech/platypush/platypush/commits/branch/master)
-since the latest release of Platypush, 7 years since [the first
-commit](https://git.platypush.tech/platypush/platypush/commit/0b0d94fee3ab20e7f488072f624b4f33c527947a),
-and 10 years since the first release of its ancestor,
-[`evesp`](https://github.com/blacklight/evesp).
-
-The past few months have been quite hectic and I have nearly rewritten the
-whole codebase, but I feel like the software is now at a stage where it's
-mature and stable enough to be used by a larger audience.
-
-The changelog [is quite
-big](https://git.platypush.tech/platypush/platypush/src/branch/master/CHANGELOG.md#1-0-0-2024-05-26),
-but it doesn't even cover all the changes, as many integrations have been
-completely rewritten.
-
-Let's go over some of the changes in the 1.0 release.
-
-## All backends are gone or turned into plugins
-
-Probably the most confusing feature of Platypush was the separation between
-backends and plugins.
-
-This was a quirk of the original implementation, where plugins were pretty much
-stateless collections of actions and backends were background tasks that
-monitored a certain integration for new events.
-
-It ended up in a state where users had to write the same configuration twice
-(e.g. one section for `light.hue` and one for `backend.light.hue`), and/or
-where me as a developer had to maintain tight dependencies between integrations
-in order for them to share configuration.
-
-Those times are now gone. Backends should only do what backends are supposed to
-do - i.e. listen for external messages and dispatch them to the application. So
-the only ones that are still there are:
-
-- [`backend.http`](https://docs.platypush.tech/platypush/backend/http.html) -
- the core Web server.
-
-- [`backend.nodered`](https://docs.platypush.tech/platypush/backend/nodered.html),
- to listen for messages from a Node-RED instance.
-
-- [`backend.redis`](https://docs.platypush.tech/platypush/backend/redis.html),
- used internally to dispatch messages across components, and it can also be
- used by external scripts to dispatch application messages on localhost
- bypassing the HTTP layer.
-
-- [`backend.tcp`](https://docs.platypush.tech/platypush/backend/tcp.html), the
- legacy (and insecure) raw TCP listener.
-
-Besides them, all the other backends have now been merged into their respective
-plugins, so no more need for dual configuration. If the former backend had a
-logic that polled at regular intervals, then you can disable polling in the
-plugin by setting `poll_interval` to `null` in the plugin configuration, so you
-can still use the plugin as a stateless entity if you wish so.
-
-This is a quite big breaking change, so you may probably want to check out the
-[plugins reference on the documentation](https://docs.platypush.tech) to check
-for any configuration changes.
-
-## Better Docker support
-
-There's now an official
-[`docker-compose.yml`](https://git.platypush.tech/platypush/platypush/src/branch/master/docker-compose.yml),
-as well as multiple Dockerfiles that support
-[Alpine](https://git.platypush.tech/platypush/platypush/src/branch/master/platypush/install/docker/alpine.Dockerfile),
-[Debian](https://git.platypush.tech/platypush/platypush/src/branch/master/platypush/install/docker/debian.Dockerfile),
-[Ubuntu](https://git.platypush.tech/platypush/platypush/src/branch/master/platypush/install/docker/ubuntu.Dockerfile)
-and
-[Fedora](https://git.platypush.tech/platypush/platypush/src/branch/master/platypush/install/docker/fedora.Dockerfile)
-base images.
-
-The `platydock` and `platyvenv` scripts have also been rewritten. They are now
-much more stable and smarter in installing any extra required dependency.
-
-## Official packages for several package managers
-
-[Official
-packages](https://git.platypush.tech/platypush/platypush#system-package-manager-installation)
-have been added for
-[Debian](https://git.platypush.tech/platypush/platypush#debian-ubuntu) and
-[Fedora](https://git.platypush.tech/platypush/platypush#fedora), on top of
-those available for [Arch Linux](https://aur.archlinux.org/packages/platypush).
-
-Official Ubuntu packages are [also on their
-way](https://git.platypush.tech/platypush/platypush/issues/368).
-
-## Better `pip` extras installation
-
-Users previously had to dig through the `setup.py` file to get the `pip` extras
-supported by specific integrations.
-
-Not anymore. Extra dependencies are now dynamically parsed from the
-integrations' `manifest.json`, so you can install them simply via `pip install
-'platypush[plugin1,plugin2,...]'`.
-
-For example, `pip install 'platypush[light.hue,music.mpd]'` to install the
-dependencies required by the `light.hue` and `music.mpd` plugins.
-
-## A more intuitive way of creating custom Python scripts
-
-### Simpler directory structure
-
-Custom scripts are loaded as Python modules. This means that you need an
-`__init__.py` in each folder that hosts some Platypush custom scripts.
-
-Earlier users were required to manually create that file, but that's no longer
-the case.
-
-You can simply drop a `.py` file in any place under your scripts directory,
-with your procedures, event hooks, crons etc., and Platypush will automatically
-pick it up.
-
-### Simpler API
-
-Earlier scripts relied on an API like this:
-
-```
-from platypush.message.event.something import SomeEvent
-from platypush.event.hook import hook
-from platypush.procedure import procedure
-from platypush.utils import run
-
-@procedure
-def my_proc(**context):
- ...
-
-@hook(SomeEvent)
-def event_hook(event, **context):
- my_proc()
-```
-
-While this API is still supported, a new simplified version is now available
-too:
-
-```
-from platypush import procedure, when, run
-from platypush.events.something import SomeEvent
-
-# Note that custom procedure name overrides are now available, albeit optional
-@procedure('this_is_my_proc')
-# Arguments are no longer a requirement, either in procedure or hooks
-def my_proc():
- ...
-
-@when(SomeEvent)
-# You can also omit event here if you don't need it
-def event_hook(event):
- # Procedures can also be called directly via `run`
- run('procedure.this_is_my_proc')
-```
-
-## Greatly improved documentation
-
-The [official documentation](https://docs.platypush.tech) has been greatly
-expanded, and it now includes all the wiki content too as well as a better UI
-for the available integrations (and also a filter bar).
-
-The documentation pages of the integrations have also been greatly improved to
-include ready-to-paste configuration snippets, installation commands for
-several package managers and a dynamically generated list of supported events
-and actions.
-
-## Removed all the custom `Response` objects
-
-Removed all `Response` objects outside of the root type. They are now all
-replaced by Marshmallow schemas with the structure automatically generated in
-the documentation.
-
-## Some new cool integrations are in
-
-The [`alarm`](https://git.platypush.tech/platypush/platypush/issues/340) plugin
-has been completely rewritten and paired to a powerful UI that allows you to
-set alarms as procedures.
-
-The old
-[`stt.picovoice.*`](https://git.platypush.tech/platypush/platypush/issues/304)
-have been replaced by a new
-[`assistant.picovoice`](https://docs.platypush.tech/platypush/plugins/assistant.picovoice.html)
-integration that provides all the features for a full-featured voice assistant.
-
-The
-[`youtube`](https://docs.platypush.tech/platypush/plugins/youtube.html) plugin
-has been rewritten too, it now relies on `yt-dlp` and it uses Piped instances
-instead of the (brittle and unstable) YouTube API. It's also been paired with a
-new UI that makes it easy to navigate your feeds, subscriptions and playlists.
-
-There's a new
-[`music.mopidy`](https://docs.platypush.tech/platypush/plugins/music.mopidy.html)
-integration too, which takes some parts of the old `music.mopidy` backend and
-add a full plugin around it which is 100% compatible with the API of the
-[`music.mpd`](https://docs.platypush.tech/platypush/plugins/music.mpd.html)
-plugin, on top of a new UI for it. This makes it easier to switch between `mpd`
-and `mopidy` implementations for your music servers, and also leverage the
-asynchronous nature of Mopidy's Web socket API to get real time events without
-polling.
-
-The `camera.pi` integration has been moved to
-[`camera.pi.legacy`](https://docs.platypush.tech/platypush/plugins/camera.pi.legacy.html)
-following the deprecation of the previous `picamera` library.
-
-[`camera.pi`](https://docs.platypush.tech/platypush/plugins/camera.pi.html) is
-now a new integration based on the recent `picamera2` module.
-
-A new
-[`openai`](https://docs.platypush.tech/platypush/plugins/openai.html)
-integration is now also available, making easy to programmatically get AI
-predictions anywhere. This can be particularly useful when paired with SST/TTS
-integrations like PicoVoice - you can implement custom voice assistants that
-use PicoVoice's libraries to do the speech/text conversion, and leverage
-ChatGPT's APIs to get plausible answers.
-
-## Some old stuff is out
-
-`google.fit` has been removed, as Google announced the deprecation of the API
-(which has already experienced stability issues for a while anyway).
-
-Same for `weather.darksky`, which has been purchased by Apple, which readily
-killed their amazing API. In turn, the `weather.openweathermap` integration has
-been empowered and it's compatible with the API of the former Darksky
-integration.
-
-The `wiimote` integration is also out. The underlying `cwiid` library hasn't
-been updated in years, and it keeps struggling with Python 3 too.
-
-Same fate goes for `stt.deepvoice`. DeepVoice was a very promising project from
-Mozilla to democratize speech-to-text, but it seems to be now abandoned, hasn't
-seen an update in years, and given Mozilla's financial woes it's unlikely to be
-resurrected any time soon.
-
-I hope that the progress on the PicoVoice integration side will make up the
-loss of the DeepSpeech integration.
-
-## And there's more to come
-
-There's a new [voice integration based on
-Whisper/GPT-4o](https://git.platypush.tech/platypush/platypush/issues/384) in
-the works too.
-
-A [dark theme for the
-UI](https://git.platypush.tech/platypush/platypush/issues/376).
-
-A new [Hue backend](https://git.platypush.tech/platypush/platypush/issues/282)
-that can make Platypush emulate the API of a Philips Hue bridge and control
-devices from the Hue app or any compatible clients.
-
-[Support for more native entities from more
-plugins](https://git.platypush.tech/platypush/platypush/milestone/4), so you
-can use the global entities view also to view cameras, control media players
-and run custom procedures.
-
-And there are two big features in the work to support [entity
-groups](https://git.platypush.tech/platypush/platypush/issues/244) and [entity
-scenes](https://git.platypush.tech/platypush/platypush/issues/245). These may
-not be must-have features anymore, now that all things can be customized with
-procedures, but it could greatly help those who come from other platforms and
-are used to these abstractions.
-
-And if you have more requests or questions, feel free to [open a
-ticket](https://git.platypush.tech/platypush/platypush/issues), [a
-PR](https://git.platypush.tech/platypush/platypush/pulls) or [ask on the Lemmy
-server](https://lemmy.platypush.tech/c/platypush).
diff --git a/markdown/Play-all-media-everywhere.md b/markdown/Play-all-media-everywhere.md
deleted file mode 100644
index 90a4024..0000000
--- a/markdown/Play-all-media-everywhere.md
+++ /dev/null
@@ -1,79 +0,0 @@
-[//]: # (title: Play all media, everywhere)
-[//]: # (description: Use Platypush to watch YouTube, Facebook and more on your favourite media player.)
-[//]: # (image: https://platypush-static.s3.nl-ams.scw.cloud/images/media-ui-1.png)
-[//]: # (author: Fabio Manganiello <fabio@platypush.tech>)
-[//]: # (published: 2024-08-18)
-
-Platypush 1.2.3 [is
-out](https://git.platypush.tech/platypush/platypush/src/branch/master/CHANGELOG.md#1-2-3),
-and the main focus of this release is on the #media side.
-
-In particular, Platypush now supports streaming/playing/downloading any media
-compatible with youtube-dl / yt-dlp, even if the upstream audio/video files are
-split - yay!
-
-This means that it's again compatible with #YouTube URLs (the integration broke
-recently after YouTube migrated all of its media to split video+audio tracks),
-and a lot of other sources that have been using this practice for a while -
-Facebook, Instagram, X, TikTok etc.
-
-It means that you can play anything that yt-dlp can digest to any supported
-media plugin - VLC, mpv, mplayer, gstreamer, Kodi or Chromecast/Miracast.
-
-Note however that mileage may vary depending on the player.
-
-Things work fine out of the box if you use `media.mpv`. MPV comes with native
-youtube-dl support, and the right stuff will be used to play the video smoothly
-if youtube-dl or yt-dlp are present on the system.
-
-[`media.vlc`](https://docs.platypush.tech/platypush/plugins/media.mpv.html) and
-[`media.gstreamer`](https://docs.platypush.tech/platypush/plugins/media.gstreamer.html)
-now provide two different play modes for YouTube-compatible content: _play on
-the fly_ and _play with cache_. In play-on-the-fly mode (default) audio and
-video content will be mixed on the fly over ffmpeg and piped to the player
-process. This means shorter load times, it's a good fit for live streams and
-large files, but it also means potentially lower media quality, high chances of
-media jitters in case of gaps in the stream being transcoded, and reduced
-ability to seek through the media. In play-with-cache mode the transcoded
-content will be cached to disk instead. It means waiting a bit longer for the
-video to load, and higher disk usage in case of large streams, but also a more
-robust and smooth playback experience.
-
-
-
-However I'm investigating a way to pass both an audio and a video URLs to
-GStreamer (it doesn't seem to be easily feasible with VLC), so the player can
-do its own tuned mixed playback without me having to reinvent the wheel. If I
-can sort it out, and manage to avoid big audio offsets in the playback process,
-then this could be the default mode for GStreamer.
-
-[`media.mplayer`](https://docs.platypush.tech/platypush/plugins/media.mplayer.html)
-only supports play-with-cache mode. The plugin already uses the player's stdin
-to communicate commands, and AFAIK MPlayer doesn't support sending both
-commands and media bytes to the player. Same goes for
-[`media.kodi`](https://docs.platypush.tech/platypush/plugins/media.kodi.html).
-
-[`media.chromecast`](https://docs.platypush.tech/platypush/plugins/media.chromecast.html)
-mileage may vary depending on the model of Chromecast. I haven't had much luck
-playing audio+video simultaneously when Platypush streams YouTube content to
-1st-gen Chromecasts because the new video codecs used by YouTube videos
-apparently aren't available on those devices. I've had mixed results by forcing
-the container to transcode the video track to H264 (and that is also the new
-default configuration for `ytdl_args` for the `media.chromecast` integration),
-but there's still a 50/50 chance that the Chromecast will only play the audio.
-I've had better luck with more recent Chromecast models though. And I believe
-that things should work just fine if you use any modern
-Miracast/DLNA-compatible device/dongle. Given the deprecation status of the
-Chromecast, and the dubious compatibility with whatever the Google TV folks are
-planning next, I'm not even sure if it's worth investing further energies in
-for the Chromecast compatibility. `media.chromecast` now also provides a
-`use_ytdl` configuration flag - it's set to true by default, but you can
-disable if you want to stream YouTube/Facebook/TikTok etc. URLs to your
-Chromecast bypassing the Platypush streaming service. This means higher chances
-that the content will play fine, but it also means that it'll be played by
-whatever compatible app (if available) runs on your Chromecast (i.e.
-ads/tracking/account limitations/geo limitations etc.).
-
-Stay tuned!
diff --git a/markdown/The-state-of-voice-assistant-integrations-in-2024.md b/markdown/The-state-of-voice-assistant-integrations-in-2024.md
deleted file mode 100644
index 4f750a0..0000000
--- a/markdown/The-state-of-voice-assistant-integrations-in-2024.md
+++ /dev/null
@@ -1,1254 +0,0 @@
-[//]: # (title: The state of voice assistant integrations in 2024)
-[//]: # (description: How to use Platypush to build your voice assistants. Featuring Google, OpenAI and Picovoice.)
-[//]: # (image: https://platypush-static.s3.nl-ams.scw.cloud/images/voice-assistant-2.png)
-[//]: # (author: Fabio Manganiello <fabio@platypush.tech>)
-[//]: # (published: 2024-06-02)
-
-Those who have been following my blog or used Platypush for a while probably
-know that I've put quite some efforts to get voice assistants rights over the
-past few years.
-
-I built my first (very primitive) voice assistant that used DCT+Markov models
-[back in 2008](https://github.com/blacklight/Voxifera), when the concept was
-still pretty much a science fiction novelty.
-
-Then I wrote [an article in
-2019](https://blog.platypush.tech/article/Build-your-customizable-voice-assistant-with-Platypush)
-and [one in
-2020](https://blog.platypush.tech/article/Build-custom-voice-assistants) on how
-to use several voice integrations in [Platypush](https://platypush.tech) to
-create custom voice assistants.
-
-## Everyone in those pictures is now dead
-
-Quite a few things have changed in this industry niche since I wrote my
-previous article. Most of the solutions that I covered back in the day,
-unfortunately, are gone in a way or another:
-
-- The `assistant.snowboy` integration is gone because unfortunately [Snowboy is
- gone](https://github.com/Kitt-AI/snowboy). For a while you could still run
- the Snowboy code with models that either you had previously downloaded from
- their website or trained yourself, but my latest experience proved to be
- quite unfruitful - it's been more than 4 years since the last commit on
- Snowboy, and it's hard to get the code to even run.
-
-- The `assistant.alexa` integration is also gone, as Amazon [has stopped
- maintaining the AVS SDK](https://github.com/alexa/avs-device-sdk). And I have
- literally no clue of what Amazon's plans with the development of Alexa skills
- are (if there are any plans at all).
-
-- The `stt.deepspeech` integration is also gone: [the project hasn't seen a
- commit in 3 years](https://github.com/mozilla/DeepSpeech) and I even
- struggled to get the latest code to run. Given the current financial
- situation at Mozilla, and the fact that they're trying to cut as much as
- possible on what they don't consider part of their core product, it's
- very unlikely that DeepSpeech will be revived any time soon.
-
-- The `assistant.google` integration [is still
- there](https://docs.platypush.tech/platypush/plugins/assistant.google.html),
- but I can't make promises on how long it can be maintained. It uses the
- [`google-assistant-library`](https://pypi.org/project/google-assistant-library/),
- which was [deprecated in
- 2019](https://developers.google.com/assistant/sdk/release-notes). Google
- replaced it with the [conversational
- actions](https://developers.google.com/assistant/sdk/), which [was also
- deprecated last year](https://developers.google.com/assistant/ca-sunset).
- `<rant>`Put here your joke about Google building products with the shelf life
- of a summer hit.`</rant>`
-
-- The `tts.mimic3` integration, a text model based on
- [mimic3](https://github.com/MycroftAI/mimic3), part of the
- [Mycroft](https://en.wikipedia.org/wiki/Mycroft_(software)) initiative, [is
- still there](https://docs.platypush.tech/platypush/plugins/tts.mimic3.html),
- but only because it's still possible to [spin up a Docker
- image](https://hub.docker.com/r/mycroftai/mimic3) that runs mimic3. The whole
- Mycroft project, however, [is now
- defunct](https://community.openconversational.ai/t/update-from-the-ceo-part-1/13268),
- and [the story of how it went
- bankrupt](https://www.reuters.com/legal/transactional/appeals-court-says-judge-favored-patent-plaintiff-scorched-earth-case-2022-03-04/)
- is a very sad story about the power that patent trolls have on startups. The
- Mycroft initiative however seems to [have been picked up by the
- community](https://community.openconversational.ai/), and something seems to
- move in the space of fully open source and on-device voice models. I'll
- definitely be looking with interest at what happens in that space, but the
- project seems to be at a stage that is still a bit immature to justify an
- investment into a new Platypush integration.
-
-## But not all hope is lost
-
-### `assistant.google`
-
-`assistant.google` may be relying on a dead library, but it's not dead (yet).
-The code still works, but you're a bit constrained on the hardware side - the
-assistant library only supports x86_64 and ARMv7 (namely, only Raspberry Pi 3
-and 4). No ARM64 (i.e. no Raspberry Pi 5), and even running it on other
-ARMv7-compatible devices has proved to be a challenge in some cases. Given the
-state of the library, it's safe to say that it'll never be supported on other
-platforms, but if you want to run your assistant on a device that is still
-supported then it should still work fine.
-
-I had however to do a few dirty packaging tricks to ensure that the assistant
-library code doesn't break badly on newer versions of Python. That code hasn't
-been touched in 5 years and it's starting to rot. It depends on ancient and
-deprecated Python libraries like [`enum34`](https://pypi.org/project/enum34/)
-and it needs some hammering to work - without breaking the whole Python
-environment in the process.
-
-For now, `pip install 'platypush[assistant.google]'` should do all the dirty
-work and get all of your assistant dependencies installed. But I can't promise
-I can maintain that code forever.
-
-### `assistant.picovoice`
-
-Picovoice has been a nice surprise in an industry niche where all the
-products that were available just 4 years ago are now dead.
-
-I described some of their products [in my previous
-articles](https://blog.platypush.tech/article/Build-custom-voice-assistants),
-and I even built a couple of `stt.picovoice.*` plugins for Platypush back in
-the day, but I didn't really put much effort in it.
-
-Their business model seemed a bit weird - along the lines of "you can test our
-products on x86_64, if you need an ARM build you should contact us as a
-business partner". And the quality of their products was also a bit
-disappointing compared to other mainstream offerings.
-
-I'm glad to see that the situation has changed quite a bit now. They still have
-a "sign up with a business email" model, but at least now you can just sign up
-on their website and start using their products rather than sending emails
-around. And I'm also quite impressed to see the progress on their website. You
-can now train hotword models, customize speech-to-text models and build your
-own intent rules directly from their website - a feature that was also
-available in the beloved Snowboy and that went missing from any major product
-offerings out there after Snowboy was gone. I feel like the quality of their
-models has also greatly improved compared to the last time I checked them -
-predictions are still slower than the Google Assistant, definitely less
-accurate with non-native accents, but the gap with the Google Assistant when it
-comes to native accents isn't very wide.
-
-### `assistant.openai`
-
-OpenAI has filled many gaps left by all the casualties in the voice assistants
-market. Platypush now provides a new `assistant.openai` plugin that stitches
-together several of their APIs to provide a voice assistant experience that
-honestly feels much more natural than anything I've tried in all these years.
-
-Let's explore how to use these integrations to build our on-device voice
-assistant with custom rules.
-
-## Feature comparison
-
-As some of you may know, voice assistant often aren't monolithic products.
-Unless explicitly designed as all-in-one packages (like the
-`google-assistant-library`), voice assistant integrations in Platypush are
-usually built on top of four distinct APIs:
-
-1. **Hotword detection**: This is the component that continuously listens on
- your microphone until you speak "Ok Google", "Alexa" or any other wake-up
- word used to start a conversation. Since it's a continuously listening
- component that needs to take decisions fast, and it only has to recognize
- one word (or in a few cases 3-4 more at most), it usually doesn't need to
- run on a full language model. It needs small models, often a couple of MBs
- heavy at most.
-
-2. **Speech-to-text** (*STT*): This is the component that will capture audio
- from the microphone and use some API to transcribe it to text.
-
-3. **Response engine**: Once you have the transcription of what the user said,
- you need to feed it to some model that will generate some human-like
- response for the question.
-
-4. **Text-to-speech** (*TTS*): Once you have your AI response rendered as a
- text string, you need a text-to-speech model to speak it out loud on your
- speakers or headphones.
-
-On top of these basic building blocks for a voice assistant, some integrations
-may also provide two extra features.
-
-#### Speech-to-intent
-
-In this mode, the user's prompt, instead of being transcribed directly to text,
-is transcribed into a structured *intent* that can be more easily processed by
-a downstream integration with no need for extra text parsing, regular
-expressions etc.
-
-For instance, a voice command like "*turn off the bedroom lights*" could be
-translated into an intent such as:
-
-```json
-{
- "intent": "lights_ctrl",
- "slots": {
- "state": "off",
- "lights": "bedroom"
- }
-}
-```
-
-#### Offline speech-to-text
-
-a.k.a. *offline text transcriptions*. Some assistant integrations may offer you
-the ability to pass some audio file and transcribe their content as text.
-
-### Features summary
-
-This table summarizes how the `assistant` integrations available in Platypush
-compare when it comes to what I would call the *foundational* blocks:
-
-| Plugin | Hotword | STT | AI responses | TTS |
-| --------------------- | ------- | --- | ------------ | --- |
-| `assistant.google` | ✅ | ✅ | ✅ | ✅ |
-| `assistant.openai` | ❌ | ✅ | ✅ | ✅ |
-| `assistant.picovoice` | ✅ | ✅ | ❌ | ✅ |
-
-And this is how they compare in terms of extra features:
-
-| Plugin | Intents | Offline SST |
-| --------------------- | ------- | ------------|
-| `assistant.google` | ❌ | ❌ |
-| `assistant.openai` | ❌ | ✅ |
-| `assistant.picovoice` | ✅ | ✅ |
-
-Let's see a few configuration examples to better understand the pros and cons
-of each of these integrations.
-
-## Configuration
-
-### Hardware requirements
-
-1. A computer, a Raspberry Pi, an old tablet, or anything in between, as long
- as it can run Python. At least 1GB of RAM is advised for smooth audio
- processing experience.
-
-2. A microphone.
-
-3. Speaker/headphones.
-
-### Installation notes
-
-[Platypush
-1.0.0](https://git.platypush.tech/platypush/platypush/src/branch/master/CHANGELOG.md#1-0-0-2024-05-26)
-has [recently been
-released](https://blog.platypush.tech/article/Platypush-1.0-is-out), and [new
-installation procedures](https://docs.platypush.tech/wiki/Installation.html)
-with it.
-
-There's now official support for [several package
-managers](https://docs.platypush.tech/wiki/Installation.html#system-package-manager-installation),
-a better [Docker installation
-process](https://docs.platypush.tech/wiki/Installation.html#docker), and more
-powerful ways to [install
-plugins](https://docs.platypush.tech/wiki/Plugins-installation.html) - via
-[`pip` extras](https://docs.platypush.tech/wiki/Plugins-installation.html#pip),
-[Web
-interface](https://docs.platypush.tech/wiki/Plugins-installation.html#web-interface),
-[Docker](https://docs.platypush.tech/wiki/Plugins-installation.html#docker) and
-[virtual
-environments](https://docs.platypush.tech/wiki/Plugins-installation.html#virtual-environment).
-
-The optional dependencies for any Platypush plugins can be installed via `pip`
-extras in the simplest case:
-
-```
-$ pip install 'platypush[plugin1,plugin2,...]'
-```
-
-For example, if you want to install Platypush with the dependencies for
-`assistant.openai` and `assistant.picovoice`:
-
-```
-$ pip install 'platypush[assistant.openai,assistant.picovoice]'
-```
-
-Some plugins however may require extra system dependencies that are not
-available via `pip` - for instance, both the OpenAI and Picovoice integrations
-require the `ffmpeg` binary to be installed, as it is used for audio
-conversion and exporting purposes. You can check the [plugins
-documentation](https://docs.platypush.tech) for any system dependencies
-required by some integrations, or install them automatically through the Web
-interface or the `platydock` command for Docker containers.
-
-### A note on the hooks
-
-All the custom actions in this article are built through event hooks triggered
-by
-[`SpeechRecognizedEvent`](https://docs.platypush.tech/platypush/events/assistant.html#platypush.message.event.assistant.SpeechRecognizedEvent)
-(or
-[`IntentRecognizedEvent`](https://docs.platypush.tech/platypush/events/assistant.html#platypush.message.event.assistant.IntentRecognizedEvent)
-for intents). When an intent event is triggered, or a speech event with a
-condition on a phrase, the `assistant` integrations in Platypush will prevent
-the default assistant response. That's to avoid cases where e.g. you say "*turn
-off the lights*", your hook takes care of running the actual action, while your
-voice assistant fetches a response from Google or ChatGPT along the lines of
-"*sorry, I can't control your lights*".
-
-If you want to render a custom response from an event hook, you can do so by
-calling `event.assistant.render_response(text)`, and it will be spoken using
-the available text-to-speech integration.
-
-If you want to disable this behaviour, and you want the default assistant
-response to always be rendered, even if it matches a hook with a phrase or an
-intent, you can do so by setting the `stop_conversation_on_speech_match`
-parameter to `false` in your assistant plugin configuration.
-
-### Text-to-speech
-
-Each of the available `assistant` plugins has it own default `tts` plugin associated:
-
-- `assistant.google`:
- [`tts`](https://docs.platypush.tech/platypush/plugins/tts.html), but
- [`tts.google`](https://docs.platypush.tech/platypush/plugins/tts.google.html)
- is also available. The difference is that `tts` uses the (unofficial) Google
- Translate frontend API - it requires no extra configuration, but besides
- setting the input language it isn't very configurable. `tts.google` on the
- other hand uses the [Google Cloud Translation
- API](https://cloud.google.com/translate/docs/reference/rest/). It is much
- more versatile, but it requires an extra API registered to your Google
- project and an extra credentials file.
-
-- `assistant.openai`:
- [`tts.openai`](https://docs.platypush.tech/platypush/plugins/tts.openai.html),
- which leverages the [OpenAI
- text-to-speech API](https://platform.openai.com/docs/guides/text-to-speech).
-
-- `assistant.picovoice`:
- [`tts.picovoice`](https://docs.platypush.tech/platypush/plugins/tts.picovoice.html),
- which uses the (still experimental, at the time of writing) [Picovoice Orca
- engine](https://github.com/Picovoice/orca).
-
-Any text rendered via `assistant*.render_response` will be rendered using the
-associated TTS plugin. You can however customize it by setting `tts_plugin` on
-your assistant plugin configuration - e.g. you can render responses from the
-OpenAI assistant through the Google or Picovoice engine, or the other way
-around.
-
-`tts` plugins also expose a `say` action that can be called outside of an
-assistant context to render custom text at runtime - for example, from other
-[event
-hooks](https://docs.platypush.tech/wiki/Quickstart.html#turn-on-the-lights-when-i-say-so),
-[procedures](https://docs.platypush.tech/wiki/Quickstart.html#greet-me-with-lights-and-music-when-i-come-home),
-[cronjobs](https://docs.platypush.tech/wiki/Quickstart.html#turn-off-the-lights-at-1-am)
-or [API calls](https://docs.platypush.tech/wiki/APIs.html). For example:
-
-```bash
-$ curl -XPOST -H "Authorization: Bearer $TOKEN" -d '
-{
- "type": "request",
- "action": "tts.openai.say",
- "args": {
- "text": "What a wonderful day!"
- }
-}
-' http://localhost:8008/execute
-```
-
-
-### `assistant.google`
-
-- [**Plugin documentation**](https://docs.platypush.tech/platypush/plugins/assistant.google.html)
-- `pip` installation: `pip install 'platypush[assistant.google]'`
-
-This is the oldest voice integration in Platypush - and one of the use-cases
-that actually motivated me into forking the [previous
-project](https://github.com/blacklight/evesp) into what is now Platypush.
-
-As mentioned in the previous section, this integration is built on top of a
-deprecated library (with no available alternatives) that just so happens to
-still work with a bit of hammering on x86_64 and Raspberry Pi 3/4.
-
-Personally it's the voice assistant I still use on most of my devices, but it's
-definitely not guaranteed that it will keep working in the future.
-
-Once you have installed Platypush with the dependencies for this integration,
-you can configure it through these steps:
-
-1. Create a new project on the [Google developers
- console](https://console.cloud.google.com) and [generate a new set of
- credentials for it](https://console.cloud.google.com/apis/credentials).
- Download the credentials secrets as JSON.
-2. Generate [scoped
- credentials](https://developers.google.com/assistant/sdk/guides/library/python/embed/install-sample#generate_credentials)
- from your `secrets.json`.
-3. Configure the integration in your `config.yaml` for Platypush (see the
- [configuration
- page](https://docs.platypush.tech/wiki/Configuration.html#configuration-file)
- for more details):
-
-```yaml
-assistant.google:
- # Default: ~/.config/google-oauthlib-tool/credentials.json
- # or <PLATYPUSH_WORKDIR>/credentials/google/assistant.json
- credentials_file: /path/to/credentials.json
- # Default: no sound is played when "Ok Google" is detected
- conversation_start_sound: /path/to/sound.mp3
-```
-
-Restart the service, say "Ok Google" or "Hey Google" while the microphone is
-active, and everything should work out of the box.
-
-You can now start creating event hooks to execute your custom voice commands.
-For example, if you configured a lights plugin (e.g.
-[`light.hue`](https://docs.platypush.tech/platypush/plugins/light.hue.html))
-and a music plugin (e.g.
-[`music.mopidy`](https://docs.platypush.tech/platypush/plugins/music.mopidy.html)),
-you can start building voice commands like these:
-
-```python
-# Content of e.g. /path/to/config_yaml/scripts/assistant.py
-
-from platypush import run, when
-from platypush.events.assistant import (
- ConversationStartEvent, SpeechRecognizedEvent
-)
-
-light_plugin = "light.hue"
-music_plugin = "music.mopidy"
-
-@when(ConversationStartEvent)
-def pause_music_when_conversation_starts():
- run(f"{music_plugin}.pause_if_playing")
-
-# Note: (limited) support for regular expressions on `phrase`
-# This hook will match any phrase containing either "turn on the lights"
-# or "turn off the lights"
-@when(SpeechRecognizedEvent, phrase="turn on (the)? lights")
-def lights_on_command():
- run(f"{light_plugin}.on")
- # Or, with arguments:
- # run(f"{light_plugin}.on", groups=["Bedroom"])
-
-@when(SpeechRecognizedEvent, phrase="turn off (the)? lights")
-def lights_off_command():
- run(f"{light_plugin}.off")
-
-@when(SpeechRecognizedEvent, phrase="play (the)? music")
-def play_music_command():
- run(f"{music_plugin}.play")
-
-@when(SpeechRecognizedEvent, phrase="stop (the)? music")
-def stop_music_command():
- run(f"{music_plugin}.stop")
-```
-
-Or, via YAML:
-
-```yaml
-# Add to your config.yaml, or to one of the files included in it
-
-event.hook.pause_music_when_conversation_starts:
- if:
- type: platypush.message.event.ConversationStartEvent
-
- then:
- - action: music.mopidy.pause_if_playing
-
-event.hook.lights_on_command:
- if:
- type: platypush.message.event.SpeechRecognizedEvent
- phrase: "turn on (the)? lights"
-
- then:
- - action: light.hue.on
- # args:
- # groups:
- # - Bedroom
-
-event.hook.lights_off_command:
- if:
- type: platypush.message.event.SpeechRecognizedEvent
- phrase: "turn off (the)? lights"
-
- then:
- - action: light.hue.off
-
-event.hook.play_music_command:
- if:
- type: platypush.message.event.SpeechRecognizedEvent
- phrase: "play (the)? music"
-
- then:
- - action: music.mopidy.play
-
-event.hook.stop_music_command:
- if:
- type: platypush.message.event.SpeechRecognizedEvent
- phrase: "stop (the)? music"
-
- then:
- - action: music.mopidy.stop
-```
-
-Parameters are also supported on the `phrase` event argument through the `${}` template construct. For example:
-
-```python
-from platypush import when, run
-from platypush.events.assistant import SpeechRecognizedEvent
-
-@when(SpeechRecognizedEvent, phrase='play ${title} by ${artist}')
-def on_play_track_command(
- event: SpeechRecognizedEvent, title: str, artist: str
-):
- results = run(
- "music.mopidy.search",
- filter={"title": title, "artist": artist}
- )
-
- if not results:
- event.assistant.render_response(f"Couldn't find {title} by {artist}")
- return
-
- run("music.mopidy.play", resource=results[0]["uri"])
-```
-
-#### Pros
-
-- 👍 Very fast and robust API.
-- 👍 Easy to install and configure.
-- 👍 It comes with almost all the features of a voice assistant installed on
- Google hardware - except some actions native to Android-based devices and
- video/display features. This means that features such as timers, alarms,
- weather forecast, setting the volume or controlling Chromecasts on the same
- network are all supported out of the box.
-- 👍 It connects to your Google account (can be configured from your Google
- settings), so things like location-based suggestions and calendar events are
- available. Support for custom actions and devices configured in your Google
- Home app is also available out of the box, although I haven't tested it in a
- while.
-- 👍 Good multi-language support. In most of the cases the assistant seems
- quite capable of understanding questions in multiple language and respond in
- the input language without any further configuration.
-
-#### Cons
-
-- 👎 Based on a deprecated API that could break at any moment.
-- 👎 Limited hardware support (only x86_64 and RPi 3/4).
-- 👎 Not possible to configure the hotword - only "Ok/Hey Google" is available.
-- 👎 Not possible to configure the output voice - it can only use the stock
- Google Assistant voice.
-- 👎 No support for intents - something similar was available (albeit tricky to
- configure) through the Actions SDK, but that has also been abandoned by
- Google.
-- 👎 Not very modular. Both `assistant.picovoice` and `assistant.openai` have
- been built by stitching together different independent APIs. Those plugins
- are therefore quite *modular*. You can choose for instance to run only the
- hotword engine of `assistant.picovoice`, which in turn will trigger the
- conversation engine of `assistant.openai`, and maybe use `tts.google` to
- render the responses. By contrast, given the relatively monolithic nature of
- `google-assistant-library`, which runs the whole service locally, if your
- instance runs `assistant.google` then it can't run other assistant plugins.
-
-### `assistant.picovoice`
-
-- [**Plugin
- documentation**](https://docs.platypush.tech/platypush/plugins/assistant.picovoice.html)
-- `pip` installation: `pip install 'platypush[assistant.picovoice]'`
-
-The `assistant.picovoice` integration is available from [Platypush
-1.0.0](https://git.platypush.tech/platypush/platypush/src/branch/master/CHANGELOG.md#1-0-0-2024-05-26).
-
-Previous versions had some outdated `sst.picovoice.*` plugins for the
-individual products, but they weren't properly tested and they weren't combined
-together into a single integration that implements the Platypush' `assistant`
-API.
-
-This integration is built on top of the voice products developed by
-[Picovoice](https://picovoice.ai/). These include:
-
-- [**Porcupine**](https://picovoice.ai/platform/porcupine/): a fast and
- customizable engine for hotword/wake-word detection. It can be enabled by
- setting `hotword_enabled` to `true` in the `assistant.picovoice` plugin
- configuration.
-
-- [**Cheetah**](https://picovoice.ai/docs/cheetah/): a speech-to-text engine
- optimized for real-time transcriptions. It can be enabled by setting
- `stt_enabled` to `true` in the `assistant.picovoice` plugin configuration.
-
-- [**Leopard**](https://picovoice.ai/docs/leopard/): a speech-to-text engine
- optimized for offline transcriptions of audio files.
-
-- [**Rhino**](https://picovoice.ai/docs/rhino/): a speech-to-intent engine.
-
-- [**Orca**](https://picovoice.ai/docs/orca/): a text-to-speech engine.
-
-You can get your personal access key by signing up at the [Picovoice
-console](https://console.picovoice.ai/). You may be asked to submit a reason
-for using the service (feel free to mention a personal Platypush integration),
-and you will receive your personal access key.
-
-If prompted to select the products you want to use, make sure to select
-the ones from the Picovoice suite that you want to use with the
-`assistant.picovoice` plugin.
-
-A basic plugin configuration would like this:
-
-```yaml
-assistant.picovoice:
- access_key: YOUR_ACCESS_KEY
-
- # Keywords that the assistant should listen for
- keywords:
- - alexa
- - computer
- - ok google
-
- # Paths to custom keyword files
- # keyword_paths:
- # - ~/.local/share/picovoice/keywords/linux/custom_linux.ppn
-
- # Enable/disable the hotword engine
- hotword_enabled: true
- # Enable the STT engine
- stt_enabled: true
-
- # conversation_start_sound: ...
-
- # Path to a custom model to be used to speech-to-text
- # speech_model_path: ~/.local/share/picovoice/models/cheetah/custom-en.pv
-
- # Path to an intent model. At least one custom intent model is required if
- # you want to enable intent detection.
- # intent_model_path: ~/.local/share/picovoice/models/rhino/custom-en-x86.rhn
-```
-
-#### Hotword detection
-
-If enabled through the `hotword_enabled` parameter (default: True), the
-assistant will listen for a specific wake word before starting the
-speech-to-text or intent recognition engines. You can specify custom models for
-your hotword (e.g. on the same device you may use "Alexa" to trigger the
-speech-to-text engine in English, "Computer" to trigger the speech-to-text
-engine in Italian, and "Ok Google" to trigger the intent recognition engine).
-
-You can also create your custom hotword models using the [Porcupine
-console](https://console.picovoice.ai/ppn).
-
-If `hotword_enabled` is set to True, you must also specify the `keywords`
-parameter with the list of keywords that you want to listen for, and optionally
-the `keyword_paths` parameter with the paths to the any custom hotword models
-that you want to use. If `hotword_enabled` is set to False, then the assistant
-won't start listening for speech after the plugin is started, and you will need
-to programmatically start the conversation by calling the
-`assistant.picovoice.start_conversation` action.
-
-When a wake-word is detected, the assistant will emit a
-[`HotwordDetectedEvent`](https://docs.platypush.tech/platypush/events/assistant.html#platypush.message.event.assistant.HotwordDetectedEvent)
-that you can use to build your custom logic.
-
-By default, the assistant will start listening for speech after the hotword if
-either `stt_enabled` or `intent_model_path` are set. If you don't want the
-assistant to start listening for speech after the hotword is detected (for
-example because you want to build your custom response flows, or trigger the
-speech detection using different models depending on the hotword that is used,
-or because you just want to detect hotwords but not speech), then you can also
-set the `start_conversation_on_hotword` parameter to `false`. If that is the
-case, then you can programmatically start the conversation by calling the
-`assistant.picovoice.start_conversation` method in your event hooks:
-
-```python
-from platypush import when, run
-from platypush.message.event.assistant import HotwordDetectedEvent
-
-# Start a conversation using the Italian language model when the
-# "Buongiorno" hotword is detected
-@when(HotwordDetectedEvent, hotword='Buongiorno')
-def on_it_hotword_detected(event: HotwordDetectedEvent):
- event.assistant.start_conversation(model_file='path/to/it.pv')
-```
-
-#### Speech-to-text
-
-If you want to build your custom STT hooks, the approach is the same seen for
-the `assistant.google` plugins - create an event hook on
-[`SpeechRecognizedEvent`](https://docs.platypush.tech/platypush/events/assistant.html#platypush.message.event.assistant.SpeechRecognizedEvent)
-with a given exact phrase, regex or template.
-
-#### Speech-to-intent
-
-
-*Intents* are structured actions parsed from unstructured human-readable text.
-
-Unlike with hotword and speech-to-text detection, you need to provide a
-custom model for intent detection. You can create your custom model using
-the [Rhino console](https://console.picovoice.ai/rhn).
-
-When an intent is detected, the assistant will emit an
-[`IntentRecognizedEvent`](https://docs.platypush.tech/platypush/events/assistant.html#platypush.message.event.assistant.IntentRecognizedEvent)
-and you can build your custom hooks on it.
-
-For example, you can build a model to control groups of smart lights by
-defining the following slots on the Rhino console:
-
-- ``device_state``: The new state of the device (e.g. with ``on`` or
- ``off`` as supported values)
-
-- ``room``: The name of the room associated to the group of lights to
- be controlled (e.g. ``living room``, ``kitchen``, ``bedroom``)
-
-You can then define a ``lights_ctrl`` intent with the following expressions:
-
-- "*turn ``$device_state:state`` the lights*"
-- "*turn ``$device_state:state`` the ``$room:room`` lights*"
-- "*turn the lights ``$device_state:state``*"
-- "*turn the ``$room:room`` lights ``$device_state:state``*"
-- "*turn ``$room:room`` lights ``$device_state:state``*"
-
-This intent will match any of the following phrases:
-
-- "*turn on the lights*"
-- "*turn off the lights*"
-- "*turn the lights on*"
-- "*turn the lights off*"
-- "*turn on the living room lights*"
-- "*turn off the living room lights*"
-- "*turn the living room lights on*"
-- "*turn the living room lights off*"
-
-And it will extract any slots that are matched in the phrases in the
-[`IntentRecognizedEvent`](https://docs.platypush.tech/platypush/events/assistant.html#platypush.message.event.assistant.IntentRecognizedEvent).
-
-Train the model, download the context file, and pass the path on the
-``intent_model_path`` parameter.
-
-You can then register a hook to listen to a specific intent:
-
-```python
-from platypush import when, run
-from platypush.events.assistant import IntentRecognizedEvent
-
-@when(IntentRecognizedEvent, intent='lights_ctrl', slots={'state': 'on'})
-def on_turn_on_lights(event: IntentRecognizedEvent):
- room = event.slots.get('room')
- if room:
- run("light.hue.on", groups=[room])
- else:
- run("light.hue.on")
-```
-
-Note that if both `stt_enabled` and `intent_model_path` are set, then
-both the speech-to-text and intent recognition engines will run in parallel
-when a conversation is started.
-
-The intent engine is usually faster, as it has a smaller set of intents to
-match and doesn't have to run a full speech-to-text transcription. This means that,
-if an utterance matches both a speech-to-text phrase and an intent, the
-`IntentRecognizedEvent` event is emitted (and not `SpeechRecognizedEvent`).
-
-This may not be always the case though. So, if you want to use the intent
-detection engine together with the speech detection, it may be a good practice
-to also provide a fallback `SpeechRecognizedEvent` hook to catch the text if
-the speech is not recognized as an intent:
-
-```python
-from platypush import when, run
-from platypush.events.assistant import SpeechRecognizedEvent
-
-@when(SpeechRecognizedEvent, phrase='turn ${state} (the)? ${room} lights?')
-def on_turn_on_lights(event: SpeechRecognizedEvent, phrase, room, **context):
- if room:
- run("light.hue.on", groups=[room])
- else:
- run("light.hue.on")
-```
-
-#### Text-to-speech and response management
-
-The text-to-speech engine, based on Orca, is provided by the
-[`tts.picovoice`](https://docs.platypush.tech/platypush/plugins/tts.picovoice.html)
-plugin.
-
-However, the Picovoice integration won't provide you with automatic
-AI-generated responses for your queries. That's because Picovoice doesn't seem
-to offer (yet) any products for conversational assistants, either voice-based
-or text-based.
-
-You can however leverage the `render_response` action to render some text as
-speech in response to a user command, and that in turn will leverage the
-Picovoice TTS plugin to render the response.
-
-For example, the following snippet provides a hook that:
-
-- Listens for `SpeechRecognizedEvent`.
-
-- Matches the phrase against a list of predefined commands that shouldn't
- require an AI-generated response.
-
-- Has a fallback logic that leverages `openai.get_response` to generate a
- response through a ChatGPT model and render it as audio.
-
-Also, note that any text rendered over the `render_response` action that ends
-with a question mark will automatically trigger a follow-up - i.e. the
-assistant will wait for the user to answer its question.
-
-```python
-import re
-
-from platypush import hook, run
-from platypush.message.event.assistant import SpeechRecognizedEvent
-
-def play_music():
- run("music.mopidy.play")
-
-def stop_music():
- run("music.mopidy.stop")
-
-def ai_assist(event: SpeechRecognizedEvent):
- response = run("openai.get_response", prompt=event.phrase)
- if not response:
- return
-
- run("assistant.picovoice.render_response", text=response)
-
-# List of commands to match, as pairs of regex patterns and the
-# corresponding actions
-hooks = (
- (re.compile(r"play (the)?music", re.IGNORECASE), play_music),
- (re.compile(r"stop (the)?music", re.IGNORECASE), stop_music),
- # ...
- # Fallback to the AI assistant
- (re.compile(r".*"), ai_assist),
-)
-
-@when(SpeechRecognizedEvent)
-def on_speech_recognized(event, **kwargs):
- for pattern, command in hooks:
- if pattern.search(event.phrase):
- run("logger.info", msg=f"Running voice command: {command.__name__}")
- command(event, **kwargs)
- break
-```
-
-#### Offline speech-to-text
-
-An [`assistant.picovoice.transcribe`
-action](https://docs.platypush.tech/platypush/plugins/assistant.picovoice.html#platypush.plugins.assistant.picovoice.AssistantPicovoicePlugin.transcribe)
-is provided for offline transcriptions of audio files, using the Leopard
-models.
-
-You can easily call it from your procedures, hooks or through the API:
-
-```bash
-$ curl -XPOST -H "Authorization: Bearer $TOKEN" -d '
-{
- "type": "request",
- "action": "assistant.picovoice.transcribe",
- "args": {
- "audio_file": "/path/to/some/speech.mp3"
- }
-}' http://localhost:8008/execute
-
-{
- "transcription": "This is a test",
- "words": [
- {
- "word": "this",
- "start": 0.06400000303983688,
- "end": 0.19200000166893005,
- "confidence": 0.9626294374465942
- },
- {
- "word": "is",
- "start": 0.2879999876022339,
- "end": 0.35199999809265137,
- "confidence": 0.9781675934791565
- },
- {
- "word": "a",
- "start": 0.41600000858306885,
- "end": 0.41600000858306885,
- "confidence": 0.9764975309371948
- },
- {
- "word": "test",
- "start": 0.5120000243186951,
- "end": 0.8320000171661377,
- "confidence": 0.9511580467224121
- }
- ]
-}
-```
-
-#### Pros
-
-- 👍 The Picovoice integration is extremely configurable. `assistant.picovoice`
- stitches together five independent products developed by a small company
- specialized in voice products for developers. As such, Picovoice may be the
- best option if you have custom use-cases. You can pick which features you
- need (hotword, speech-to-text, speech-to-intent, text-to-speech...) and you
- have plenty of flexibility in building your integrations.
-
-- 👍 Runs (or seems to run) (mostly) on device. This is something that we can't
- say about the other two integrations discussed in this article. If keeping
- your voice interactions 100% hidden from Google's or Microsoft's eyes is a
- priority, then Picovoice may be your best bet.
-
-- 👍 Rich features. It uses different models for different purposes - for
- example, Cheetah models are optimized for real-time speech detection, while
- Leopard is optimized for offline transcription. Moreover, Picovoice is the
- only integration among those analyzed in this article to support
- speech-to-intent.
-
-- 👍 It's very easy to build new models or customize existing ones. Picovoice
- has a powerful developers console that allows you to easily create hotword
- models, tweak the priority of some words in voice models, and create custom
- intent models.
-
-#### Cons
-
-- 👎 The business model is still a bit weird. It's better than the earlier
- "*write us an email with your business case and we'll reach back to you*",
- but it still requires you to sign up with a business email and write a couple
- of lines on what you want to build with their products. It feels like their
- focus is on a B2B approach rather than "open up and let the community build
- stuff", and that seems to create unnecessary friction.
-
-- 👎 No native conversational features. At the time of writing, Picovoice
- doesn't offer products that generate AI responses given voice or text
- prompts. This means that, if you want AI-generated responses to your queries,
- you'll have to do requests to e.g.
- [`openai.get_response(prompt)`](https://docs.platypush.tech/platypush/plugins/openai.html#platypush.plugins.openai.OpenaiPlugin.get_response)
- directly in your hooks for `SpeechRecognizedEvent`, and render the responses
- through `assistant.picovoice.render_response`. This makes the use of
- `assistant.picovoice` alone more fit to cases where you want to mostly create
- voice command hooks rather than have general-purpose conversations.
-
-- 👎 Speech-to-text, at least on my machine, is slower than the other two
- integrations, and the accuracy with non-native accents is also much lower.
-
-- 👎 Limited support for any languages other than English. At the time of
- writing hotword detection with Porcupine seems to be in a relative good shape
- with [support for 16
- languages](https://github.com/Picovoice/porcupine/tree/master/lib/common).
- However, both speech-to-text and text-to-speech only support English at the
- moment.
-
-- 👎 Some APIs are still quite unstable. The Orca text-to-speech API, for
- example, doesn't even support text that includes digits or some punctuation
- characters - at least not at the time of writing. The Platypush integration
- fills the gap with workarounds that e.g. replace words to numbers and replace
- punctuation characters, but you definitely have a feeling that some parts of
- their products are still work in progress.
-
-### `assistant.openai`
-
-- [**Plugin
- documentation**](https://docs.platypush.tech/platypush/plugins/assistant.openai.html)
-- `pip` installation: `pip install 'platypush[assistant.openai]'`
-
-This integration has been released in [Platypush
-1.0.7](https://git.platypush.tech/platypush/platypush/src/branch/master/CHANGELOG.md#1-0-7-2024-06-02).
-
-It uses the following OpenAI APIs:
-
-- [`/audio/transcriptions`](https://platform.openai.com/docs/guides/speech-to-text)
- for speech-to-text. At the time of writing the default model is `whisper-1`.
- It can be configured through the `model` setting on the `assistant.openai`
- plugin configuration. See the [OpenAI
- documentation](https://platform.openai.com/docs/models/whisper) for a list of
- available models.
-- [`/chat/completions`](https://platform.openai.com/docs/api-reference/completions/create)
- to get AI-generated responses using a GPT model. At the time of writing the
- default is `gpt-3.5-turbo`, but it can be configurable through the `model`
- setting on the `openai` plugin configuration. See the [OpenAI
- documentation](https://platform.openai.com/docs/models) for a list of supported models.
-- [`/audio/speech`](https://platform.openai.com/docs/guides/text-to-speech) for
- text-to-speech. At the time of writing the default model is `tts-1` and the
- default voice is `nova`. They can be configured through the `model` and
- `voice` settings respectively on the `tts.openai` plugin. See the OpenAI
- documentation for a list of available
- [models](https://platform.openai.com/docs/models/tts) and
- [voices](https://platform.openai.com/docs/guides/text-to-speech/voice-options).
-
-You will need an [OpenAI API key](https://platform.openai.com/api-keys)
-associated to your account.
-
-A basic configuration would like this:
-
-```yaml
-openai:
- api_key: YOUR_OPENAI_API_KEY # Required
- # conversation_start_sound: ...
- # model: ...
- # context: ...
- # context_expiry: ...
- # max_tokens: ...
-
-assistant.openai:
- # model: ...
- # tts_plugin: some.other.tts.plugin
-
-tts.openai:
- # model: ...
- # voice: ...
-```
-
-If you want to build your custom hooks on speech events, the approach is the
-same seen for the other `assistant` plugins - create an event hook on
-[`SpeechRecognizedEvent`](https://docs.platypush.tech/platypush/events/assistant.html#platypush.message.event.assistant.SpeechRecognizedEvent)
-with a given exact phrase, regex or template.
-
-#### Hotword support
-
-OpenAI doesn't provide an API for hotword detection, nor a small model for
-offline detection.
-
-This means that, if no other `assistant` plugins with stand-alone hotword
-support are configured (only `assistant.picovoice` for now), a conversation can
-only be triggered by calling the `assistant.openai.start_conversation` action.
-
-If you want hotword support, then the best bet is to add `assistant.picovoice`
-to your configuration too - but make sure to only enable hotword detection and
-not speech detection, which will be delegated to `assistant.openai` via event
-hook:
-
-```yaml
-assistant.picovoice:
- access_key: ...
- keywords:
- - computer
-
- hotword_enabled: true
- stt_enabled: false
- # conversation_start_sound: ...
-```
-
-Then create a hook that listens for
-[`HotwordDetectedEvent`](https://docs.platypush.tech/platypush/events/assistant.html#platypush.message.event.assistant.HotwordDetectedEvent)
-and calls `assistant.openai.start_conversation`:
-
-```python
-from platypush import run, when
-from platypush.events.assistant import HotwordDetectedEvent
-
-@when(HotwordDetectedEvent, hotword="computer")
-def on_hotword_detected():
- run("assistant.openai.start_conversation")
-```
-
-#### Conversation contexts
-
-The most powerful feature offered by the OpenAI assistant is the fact that it
-leverages the *conversation contexts* provided by the OpenAI API.
-
-This means two things:
-
-1. Your assistant can be initialized/tuned with a *static context*. It is
- possible to provide some initialization context to the assistant that can
- fine tune how the assistant will behave, (e.g. what kind of
- tone/language/approach will have when generating the responses), as well as
- initialize the assistant with some predefined knowledge in the form of
- hypothetical past conversations. Example:
-
-```yaml
-openai:
- # ...
-
- context:
- # `system` can be used to initialize the context for the expected tone
- # and language in the assistant responses
- - role: system
- content: >
- You are a voice assistant that responds to user queries using
- references to Lovecraftian lore.
-
- # `user`/`assistant` interactions can be used to initialize the
- # conversation context with previous knowledge. `user` is used to
- # emulate previous user questions, and `assistant` models the
- # expected response.
- - role: user
- content: What is a telephone?
- - role: assistant
- content: >
- A Cthulhuian device that allows you to communicate with
- otherworldly beings. It is said that the first telephone was
- created by the Great Old Ones themselves, and that it is a
- gateway to the void beyond the stars.
-```
-
- If you now start Platypush and ask a question like "*how does it work?*",
- the voice assistant may give a response along the lines of:
-
- ```
- The telephone functions by harnessing the eldritch energies of the cosmos to
- transmit vibrations through the ether, allowing communication across vast
- distances with entities from beyond the veil. Its operation is shrouded in
- mystery, for it relies on arcane principles incomprehensible to mortal
- minds.
- ```
-
- Note that:
-
- 1. The style of the response is consistent with that initialized in the
- `context` through `system` roles.
-
- 2. Even though a question like "*how does it work?*" is not very specific,
- the assistant treats the `user`/`assistant` entries given in the context
- as if they were the latest conversation prompts. Thus it realizes that
- "*it*", in this context, probably means "*the telephone*".
-
-2. The assistant has a *runtime context*. It will remember the recent
- conversations for a given amount of time (configurable through the
- `context_expiry` setting on the `openai` plugin configuration). So, even
- without explicit context initialization in the `openai` plugin, the plugin
- will remember the last interactions for (by default) 10 minutes. So if you
- ask "*who wrote the Divine Comedy?*", and a few seconds later you ask
- "*where was its writer from?*", you may get a response like "*Florence,
- Italy*" - i.e. the assistant realizes that "*the writer*" in this context is
- likely to mean "*the writer of the work that I was asked about in the
- previous interaction*" and return pertinent information.
-
-#### Pros
-
-- 👍 Speech detection quality. The OpenAI speech-to-text features are the best
- among the available `assistant` integrations. The `transcribe` API so far has
- detected my non-native English accent right nearly 100% of the times (Google
- comes close to 90%, while Picovoice trails quite behind). And it even detects
- the speech of my young kid - something that the Google Assistant library has
- always failed to do right.
-
-- 👍 Text-to-speech quality. The voice models used by OpenAI sound much more
- natural and human than those of both Google and Picovoice. Google's and
- Picovoice's TTS models are actually already quite solid, but OpenAI
- outclasses them when it comes to voice modulation, inflections and sentiment.
- The result sounds intimidatingly realistic.
-
-- 👍 AI responses quality. While the scope of the Google Assistant is somewhat
- limited by what people expected from voice assistants until a few years ago
- (control some devices and gadgets, find my phone, tell me the news/weather,
- do basic Google searches...), usually without much room for follow-ups,
- `assistant.openai` will basically render voice responses as if you were
- typing them directly to ChatGPT. While Google would often respond you with a
- "*sorry, I don't understand*", or "*sorry, I can't help with that*", the
- OpenAI assistant is more likely to expose its reasoning, ask follow-up
- questions to refine its understanding, and in general create a much more
- realistic conversation.
-
-- 👍 Contexts. They are an extremely powerful way to initialize your assistant
- and customize it to speak the way you want, and know the kind of things that
- you want it to know. Cross-conversation contexts with configurable expiry
- also make it more natural to ask something, get an answer, and then ask
- another question about the same topic a few seconds later, without having to
- reintroduce the assistant to the whole context.
-
-- 👍 Offline transcriptions available through the `openai.transcribe` action.
-
-- 👍 Multi-language support seems to work great out of the box. Ask something
- to the assistant in any language, and it'll give you a response in that
- language.
-
-- 👍 Configurable voices and models.
-
-#### Cons
-
-- 👎 The full pack of features is only available if you have an API key
- associated to a paid OpenAI account.
-
-- 👎 No hotword support. It relies on `assistant.picovoice` for hotword
- detection.
-
-- 👎 No intents support.
-
-- 👎 No native support for weather forecast, alarms, timers, integrations with
- other services/devices nor other features available out of the box with the
- Google Assistant. You can always create hooks for them though.
-
-### Weather forecast example
-
-Both the OpenAI and Picovoice integrations lack some features available out of
-the box on the Google Assistant - weather forecast, news playback, timers etc. -
-as they rely on voice-only APIs that by default don't connect to other services.
-
-However Platypush provides many plugins to fill those gaps, and those features
-can be implemented with custom event hooks.
-
-Let's see for example how to build a simple hook that delivers the weather
-forecast for the next 24 hours whenever the assistant gets a phrase that
-contains the "*weather today*" string.
-
-You'll need to enable a `weather` plugin in Platypush -
-[`weather.openweathermap`](https://docs.platypush.tech/platypush/plugins/weather.openweathermap.html)
-will be used in this example. Configuration:
-
-```yaml
-weather.openweathermap:
- token: OPENWEATHERMAP_API_KEY
- location: London,GB
-```
-
-Then drop a script named e.g. `weather.py` in the Platypush scripts directory
-(default: `<CONFDIR>/scripts`) with the following content:
-
-```python
-from datetime import datetime
-from textwrap import dedent
-from time import time
-
-from platypush import run, when
-from platypush.events.assistant import SpeechRecognizedEvent
-
-@when(SpeechRecognizedEvent, phrase='weather today')
-def weather_forecast(event: SpeechRecognizedEvent):
- limit = time() + 24 * 60 * 60 # 24 hours from now
- forecast = [
- weather
- for weather in run("weather.openweathermap.get_forecast")
- if datetime.fromisoformat(weather["time"]).timestamp() < limit
- ]
-
- min_temp = round(
- min(weather["temperature"] for weather in forecast)
- )
- max_temp = round(
- max(weather["temperature"] for weather in forecast)
- )
- max_wind_gust = round(
- (max(weather["wind_gust"] for weather in forecast)) * 3.6
- )
- summaries = [weather["summary"] for weather in forecast]
- most_common_summary = max(summaries, key=summaries.count)
- avg_cloud_cover = round(
- sum(weather["cloud_cover"] for weather in forecast) / len(forecast)
- )
-
- event.assistant.render_response(
- dedent(
- f"""
- The forecast for today is: {most_common_summary}, with
- a minimum of {min_temp} and a maximum of {max_temp}
- degrees, wind gust of {max_wind_gust} km/h, and an
- average cloud cover of {avg_cloud_cover}%.
- """
- )
- )
-```
-
-This script will work with any of the available voice assistants.
-
-You can also implement something similar for news playback, for example using
-the [`rss` plugin](https://docs.platypush.tech/platypush/plugins/rss.html) to
-get the latest items in your subscribed feeds. Or to create custom alarms using
-the [`alarm` plugin](https://docs.platypush.tech/platypush/plugins/alarm.html),
-or a timer using the [`utils.set_timeout`
-action](https://docs.platypush.tech/platypush/plugins/utils.html#platypush.plugins.utils.UtilsPlugin.set_timeout).
-
-## Conclusions
-
-The past few years have seen a lot of things happen in the voice industry.
-Many products have gone out of market, been deprecated or sunset, but not all
-hope is lost. The OpenAI and Picovoice products, especially when combined
-together, can still provide a good out-of-the-box voice assistant experience.
-And the OpenAI products have also raised the bar on what to expect from an
-AI-based assistant.
-
-I wish that there were still some fully open and on-device alternatives out
-there, now that Mycroft, Snowboy and DeepSpeech are all gone. OpenAI and Google
-provide the best voice experience as of now, but of course they come with
-trade-offs - namely the great amount of data points you feed to these
-cloud-based services. Picovoice is somewhat a trade-off, as it runs at least
-partly on-device, but their business model is still a bit fuzzy and it's not
-clear whether they intend to have their products used by the wider public or if
-it's mostly B2B.
-
-I'll keep an eye however on what is going to come from the ashes of Mycroft
-under the form of the
-[OpenConversational](https://community.openconversational.ai/) project, and
-probably keep you up-to-date when there is a new integration to share.
diff --git a/markdown/Ultimate-self-hosted-automation-with-Platypush.md b/markdown/Ultimate-self-hosted-automation-with-Platypush.md
index be0f707..f75696b 100644
--- a/markdown/Ultimate-self-hosted-automation-with-Platypush.md
+++ b/markdown/Ultimate-self-hosted-automation-with-Platypush.md
@@ -68,7 +68,7 @@ a few sensors on a small Raspberry Zero is guaranteed to take not more than 5-10
The flexibility of Platypush comes however a slightly steeper learning curve, but it rewards the user with much more
room for customization. You are expected to install it via [pip](https://pypi.org/project/platypush/) or
-the [git repo](https://git.platypush.tech/platypush/platypush), install the dependencies based on the plugins you
+the [Gitlab](https://git.platypush.tech/platypush/platypush) repo, install the dependencies based on the plugins you
want (although managing per-plugin dependencies is quite easy via `pip`), and manually create or edit a configuration
file. But it provides much, much more flexibility. It can listen for messages on MQTT, HTTP (but you don’t have to run
the webserver if you don’t want to), websocket, TCP socket, Redis, Kafka, Pushbullet — you name it, it has probably got