Added new article on Fediverse + Platypush automation
This commit is contained in:
parent
f34f1f6232
commit
af685bce16
5 changed files with 695 additions and 0 deletions
BIN
img/mastodon-screenshot-1.png
Normal file
BIN
img/mastodon-screenshot-1.png
Normal file
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 38 KiB |
BIN
img/mastodon-screenshot-2.png
Normal file
BIN
img/mastodon-screenshot-2.png
Normal file
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 8.2 KiB |
BIN
img/mastodon-screenshot-3.png
Normal file
BIN
img/mastodon-screenshot-3.png
Normal file
{kind=link}
Binary file not shown.
|
After 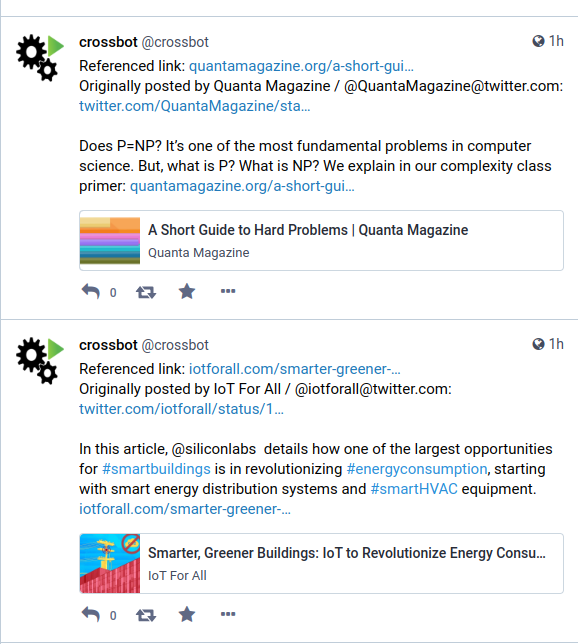
(image error) Size: 107 KiB |
BIN
img/twitter2mastodon.png
Normal file
BIN
img/twitter2mastodon.png
Normal file
{kind=link}
Binary file not shown.
|
After 
(image error) Size: 164 KiB |
|
|
@ -0,0 +1,695 @@
|
|||
[//]: # (title: Create a Mastodon bot to forward Twitter and RSS feeds to your timeline)
|
||||
[//]: # (description: Take your favourite accounts and sources with you on the Fediverse, even if they aren't there)
|
||||
[//]: # (image: /img/twitter2mastodon.png)
|
||||
[//]: # (author: Fabio Manganiello <fabio@platypush.tech>)
|
||||
[//]: # (published: 2022-05-06)
|
||||
|
||||
This article is divided in three sections:
|
||||
|
||||
1. A first section where I share some of my thoughts on the Fediverse, on the
|
||||
trade-offs between centralized and decentralized social networks, and go
|
||||
over a brief history of the protocols behind platforms like Mastodon.
|
||||
|
||||
2. A second section where I show with a practical example that leverages
|
||||
Platypush how to set up a bot that brings your favorite Twitter profiles and
|
||||
RSS feeds to your Fediverse timeline, even if they don't have an account
|
||||
there.
|
||||
|
||||
3. Some final observations on the current drawbacks of the Fediverse, with a
|
||||
particular focus on Mastodon and the current state of relaying.
|
||||
|
||||
If you are just here for the code, feel free to skip to the _Creating a
|
||||
cross-posting bot_ section and skip the last section. Otherwise, grab a coffee
|
||||
while I go over some techno/philosophical analysis of social media in 2022, how
|
||||
we got here and what the future may hold.
|
||||
|
||||
## Searching for a social safe harbor
|
||||
|
||||
My interest into the [Fediverse](https://en.wikipedia.org/wiki/Fediverse) and
|
||||
its ideas, protocols and products dates back to more than a decade.
|
||||
|
||||
I've had an account on the [centralized Diaspora
|
||||
instance](https://joindiaspora.com/) more or less since the service was spawned
|
||||
in 2010 until it shut down, even though I haven't updated it for the last
|
||||
couple of years.
|
||||
|
||||
And I've been running a [Mastodon instance](https://social.platypush.tech)
|
||||
mainly dedicated to Platypush for a while. However, I haven't advertised it
|
||||
much so far, since I haven't been spending much time on it myself until
|
||||
recently.
|
||||
|
||||
My interest in the Fediverse used to be quite sporadic until recently. Yes, I
|
||||
would rant a lot about Facebook/Meta, about the irresponsibility and greediness
|
||||
rooted deep in its culture, their very hostile and opaque approach against
|
||||
external researchers and auditors and the deeply flawed thirst for further
|
||||
centralization that motivates each of its decisions. And, whenever I got too
|
||||
sick of Facebook, I would just move my social tents to Twitter for a while.
|
||||
Which is far from perfect, but it probably used to be the least poisonous
|
||||
between the two necessary evils. As somebody how had been on alternative social
|
||||
networks for more than a decade, I know way too well the feeling of excitement
|
||||
when a new shiny toy comes in town, quickly followed by the rolling
|
||||
tumbleweeds.
|
||||
|
||||
That applies [until
|
||||
recently](https://www.economist.com/business/2022/04/23/elon-musks-twitter-saga-is-capitalism-gone-rogue).
|
||||
|
||||
I don't feel comfortable anymore sharing my thoughts and communications on a
|
||||
platform owned by the richest man on earth, which also so happens to be a chief
|
||||
troll with distorted ideas about the balance between freedom of speech and
|
||||
responsibilities for one's words.
|
||||
|
||||
So, just like [many other
|
||||
users](https://uk.pcmag.com/social-media/140065/mastodon-gains-30000-new-users-after-musk-buys-twitter)
|
||||
did after Musk's takeover, I also rushed (back) to the Fediverse as a safe and
|
||||
uncompromising solution. But, unlike the majority of them, instead of rushing
|
||||
to [mastodon.online](https://mastodon.online) (I don't like the idea of moving
|
||||
from a centralized platform/instance to another), I rushed to upgrade and
|
||||
prepare my dusty [social.platypush.tech](https://social.platypush.tech)
|
||||
instance.
|
||||
|
||||
## Give me back the old web
|
||||
|
||||
The whole idea of a Fediverse is as old as Facebook and Twitter themselves.
|
||||
|
||||
[identi.ca](https://en.wikipedia.org/wiki/Identi.ca), launched in 2008, was
|
||||
probably the first usable implementation of an open-source social network based
|
||||
on [Activity Streams](https://en.wikipedia.org/wiki/Activity_Streams_(format)),
|
||||
an open syndacation format drafted by the W3C to represent entities, accounts,
|
||||
media, posts and more across several social platforms. Considering the time
|
||||
when it was born, it was a lot influenced by the ideas of the semantic web that
|
||||
were popular at the time (it's about
|
||||
[that pre-crypto Web 3.0 that didn't
|
||||
happen](https://blog.fabiomanganiello.com/article/Web-3.0-and-the-undeliverable-promise-of-decentralization),
|
||||
at least not in this universe's timeline).
|
||||
|
||||
[GNU Social](https://gnusocial.network/) followed in 2009 (and it's still
|
||||
active today), then
|
||||
[Diaspora](https://en.wikipedia.org/wiki/Diaspora_(social_network)) in 2010
|
||||
brought the world of alternative open-source social networks into the spotlight
|
||||
for a while.
|
||||
|
||||
A lot of progress has happened since then.
|
||||
[ActivityPub](https://en.wikipedia.org/wiki/ActivityPub), another open protocol
|
||||
drafted by the W3C, has become a de-facto standard when it comes to sharing
|
||||
content across different instances and platforms. And tens of platforms
|
||||
(including Mastodon itself, Pleroma, PeerTube, Pubcast, Hubzilla, NextCloud
|
||||
Social, Friendica) currently support ActivityPub, making it possible for users
|
||||
to follow, interact and share content regardless of where it is hosted.
|
||||
|
||||
Anybody can install and run a public instance using one of these platforms, and
|
||||
anybody on that instance can follow and interact with other users, even if they
|
||||
are on other platforms, as long as those instances are publicly searchable.
|
||||
This is possible because the underlying protocols are the same, no matter who
|
||||
runs the server or what application the server runs. If I have an account on a
|
||||
Mastodon instance, I can use it to follow a video channel on a PeerTube
|
||||
instance and comment on it. Even if they run on different machines and they run
|
||||
different applications, the platforms are able to share content and ensure
|
||||
federated authentication with one another, just like your web browser can be
|
||||
used to render content from different web servers: as long as they speak the
|
||||
same protocol (in this case, HTTP), a browser can render any content,
|
||||
regardless if it comes from an Apache or a Tomcat server.
|
||||
|
||||
This is the way social networks should have been implemented from the very
|
||||
beginning. Anybody can run one, it's up to admins of instances to decide which
|
||||
other instances they want to _federate_ with (therefore importing traffic from
|
||||
other instances into a unique _federated_ timeline), and it's up to individual
|
||||
users to decide who they want to follow and therefore be part of their home
|
||||
timeline, regardless of who runs the servers where those accounts are hosted.
|
||||
|
||||
It's an idea that sits somewhere between email (you can exchange emails with
|
||||
anyone as long as you have their email address, even if you have a `@gmail.com`
|
||||
account and they have a `@hotmail.com` account, even if you use Thunderbird as
|
||||
a client and they use a web app) and RSS feeds (you can aggregate links from
|
||||
any source under the same interface, as long as that source provides an
|
||||
RSS/Atom feed).
|
||||
|
||||
And that's indeed the trajectory that social networks were projected to follow
|
||||
until the early 2010s. The W3C and ISO had worked feverishly on open protocols
|
||||
that could make the social network experience open and distributed, like the
|
||||
whole Internet had been designed to run up to that date. And implementations
|
||||
such as identi.ca, GNU Social and Diaspora were quickly popping up to showcase
|
||||
those implementations.
|
||||
|
||||
But that's not how history went in this universe, as we all know.
|
||||
|
||||
Facebook underwent an exponential growth through aggressive centralization and
|
||||
controversial data collection practices and monetization practices. Most of the
|
||||
other social networks also followed the Facebook model.
|
||||
|
||||
Open chat protocols like XMPP were gradually replaced by centralized apps with
|
||||
nearly no integrations with the outside world.
|
||||
|
||||
Open syndacation protocols like RSS and Atom were replaced by closed timelines
|
||||
curated by centralized and closely guarded algorithms. This was in part also
|
||||
due to Google killing Reader, the most used interface for feeds, because it was
|
||||
in the way of their idea of web content monetization: without a major player
|
||||
like Google who had interest in the development of those open protocols,
|
||||
innovation on RSS/Atom largely stalled.
|
||||
|
||||
Open activity pub/sub algorithms were replaced by a handful of walled gardens,
|
||||
whose concept of "data portability" often involved manually downloading a
|
||||
heavy, unsorted and often unusable zip dump of all of your data.
|
||||
|
||||
Transparent, machine-readable data access was replaced by proprietary user
|
||||
interfaces, and a few half-heartedly implemented APIs that cover only part of
|
||||
the features, and can be deprecated with nearly no notice depending on whatever
|
||||
objective a private company decides to pursue on the short term.
|
||||
|
||||
I would argue that the aggressive push towards centralization, closed protocols
|
||||
and walled gardens of the 2010s has only benefited a handful of private
|
||||
companies, while throwing a wrench in a machinery that was already working
|
||||
well, replacing it with a vision of the Web that created way more problems that
|
||||
the ones that it aimed to solve. All in all, the 5-6 companies behind that
|
||||
disaster named Web 2.0 are responsible for pushing the Web back by at least a
|
||||
decade.
|
||||
|
||||
The wave however, as it always happens in that eternal swing between
|
||||
centralization and decentralization that propels our industry, is changing. The
|
||||
drawbacks of the centralized social network model have been under everyone's
|
||||
for the past few years. The "_you can check out any time you like, but you can
|
||||
never leave, because all of your friends and relatives are here_" blackmail
|
||||
strategy starts to be less effective, because alternatives are popping up, they
|
||||
are starting to gain traction, and the bleeding of active users on Facebook and
|
||||
Twitter has been a fact for at least the past two years.
|
||||
|
||||
Facebook is aware of it, but some reason they believe that the solution to the
|
||||
problems of centralized social networks is a creepy clone of
|
||||
[SecondLife](https://secondlife.com/) that they call Metaverse. Twitter is much
|
||||
more aware of the issue, and they have in fact decided to speed up things with
|
||||
their [Bluesky
|
||||
project](https://www.theverge.com/2022/5/4/23057473/twitter-bluesky-adx-release-open-source-decentralized-social-network).
|
||||
|
||||
They have recently published a [Github
|
||||
repo](https://github.com/bluesky-social/adx) with a simple MVP consisting of a
|
||||
server, an in-memory database and a command-line interface, and a (still quite
|
||||
vague) [architecture
|
||||
document](https://github.com/bluesky-social/adx/blob/main/architecture.md) that
|
||||
resembles a lot the ActivityPub implementation, except with a more centralized
|
||||
and hierarchical control chain with a (still vaguely defined)
|
||||
consortium/committee sitting at its top, and a Blockchain-like append-only
|
||||
ledger to manage information.
|
||||
|
||||
I see Twitter's announcement as a reflex reaction to the bleeding of users
|
||||
towards decentralized platforms that happened shortly after Musk's takeover. It
|
||||
almost feels as if an engineer was rushed to push some MVP on their laptop to
|
||||
show that they have a carrot they can give to their users. But it's too little,
|
||||
too late.
|
||||
|
||||
There are nearly two decades of work behind ActivityPub. A lot of smart people
|
||||
have already figured out the (open) solutions to most of the problems. I don't
|
||||
see the value of reinventing the wheel through a solution owned by a private
|
||||
company, with a private consortium behind it, that proposes a solution that is
|
||||
largely incompatible with what the W3C has been working on since the mid 2000s.
|
||||
|
||||
And I don't trust the sincerity of Twitter and the BlueSky investors. If
|
||||
Twitter was that interested in building a decentralized social network, then
|
||||
where have they been for the past 15 years, and why haven't they contributed
|
||||
more to open protocols like ActivityPub? What's the need of yet another
|
||||
closed-access committee to design the future of social media when we already
|
||||
have the W3C?
|
||||
|
||||
It sounds like they have preferred instead to milk their centralized,
|
||||
closed-source and closed-protocol cow as long as they could (even when it was
|
||||
clear that it wasn't profitable). They have built some hype around BlueSky for
|
||||
the past two years that was all marketing talk and no architecture document
|
||||
(let alone a usable codebase), and they have rushed to push a half-baked MVP
|
||||
after the richest man on earth bought them and thousands of users opened
|
||||
accounts somewhere else - and, most of all, a lot of people realized that
|
||||
almost anybody can set up a social network server. The sudden
|
||||
Twitter❤️open-source and Twitter❤️open-protocols shift is [quite
|
||||
familiar](https://pulse.microsoft.com/nl-nl/transform-nl-nl/na/fa1-microsoft-loves-open-source/).
|
||||
Whenever it happens, it's because a company in a monopoly/oligopoly-like market
|
||||
has stopped growing, and the closed+centralized approach that made their
|
||||
fortunes (and allowed them to make profits without innovating much) has become
|
||||
too hard to maintain and scale. Whenever this happens, the company usually
|
||||
display a sudden burst of love for the open-source community, and it turns to
|
||||
them for new ideas (and to write code for their products so their engineers
|
||||
don't have to). They usually admit that the solutions proposed by the community
|
||||
and the committees for standards were right all the time, but they usually
|
||||
don't take responsibility for slowing down innovation by years while they
|
||||
dragged their feet and milked their cows. However, they still want a chance of
|
||||
running the show. They still want to lead the discussions around the new
|
||||
platforms and protocols, or at least have a majority stake in them, so they can
|
||||
more easily prepare the ground for the next step of the
|
||||
[embrace-extend-extinguish](https://en.wikipedia.org/wiki/Embrace,_extend,_and_extinguish)
|
||||
cycle. Needless to say, we should play our roles so that such strategies stop
|
||||
being successful.
|
||||
|
||||
## Is there anybody out there?
|
||||
|
||||
The open-source alternatives and the open protocols haven't succeeded in the
|
||||
past decade not because their proposed solutions were technically inferior to
|
||||
those provided by Facebook or Twitter. On the contrary, they had figured out
|
||||
the solutions to the problems of distributed moderation, federated
|
||||
authentication and cross-platform data exchange long before them.
|
||||
|
||||
They didn't succeed because it's hard to replicate the exponential snowball of
|
||||
a true network effect once all the people are already using a certain platform.
|
||||
Even if you pour a lot of time, money and resources into building an
|
||||
alternative (like Google+ tried to do for a while), people are naturally
|
||||
resistant to change, and it's just too hard to move them once all of their
|
||||
contacts are on a single platform. Especially when social networks are owned by
|
||||
private businesses that keep the barriers towards data portability artificially
|
||||
high.
|
||||
|
||||
So, even with all the advantages of a federated network of instances, the two
|
||||
titans still outweighed in an industry where the winner takes it all, and for a
|
||||
long time Mastodon and Diaspora instances were deserts comparable to Google+ -
|
||||
except for few enthusiastic niches, and for a few active instances run from
|
||||
places with strict social media limitations.
|
||||
|
||||
The wind has started to change [in April
|
||||
2022](https://www.pcmag.com/news/mastodon-sees-increase-in-user-sign-ups-after-musk-buys-twitter-stake).
|
||||
And [the EU has also recently announced further
|
||||
steps](https://www.theverge.com/2022/3/24/22995431/european-union-digital-markets-act-imessage-whatsapp-interoperable)
|
||||
in enforcing their [vision for greater digital
|
||||
interoperability](https://www.eff.org/deeplinks/2020/06/our-eu-policy-principles-interoperability).
|
||||
|
||||
After the early April diaspora I picked up my instance again, started following
|
||||
some new interesting accounts and federating with some relays, and there's now
|
||||
enough activity for me to use my Mastodon instance as my daily social driver.
|
||||
Even if the scale of the Mastodon network (around 3-4 million users) still
|
||||
pales in comparison to that of Facebook's empire, it starts to be a
|
||||
considerable fraction of Twitter's active (human) user base.
|
||||
|
||||
However, even if many influential accounts have moved to Mastodon (or at least
|
||||
they cross-post to Mastodon), such as [The
|
||||
Guardian](https://mstdn.social/@TheGuardian), [Hacker
|
||||
News](https://mastodon.social/@hn_discussions) and the [official EU News
|
||||
channel](https://eupublic.social/@eunews), there is still a big gap in terms of
|
||||
accounts and content that are only available on Twitter/Facebook.
|
||||
|
||||
So I took some initiative, and decided that if the mountain doesn't come to me,
|
||||
then I'll move it to me myself.
|
||||
|
||||
## Creating a cross-posting bot
|
||||
|
||||
There are a lot of amazing profiles to follow on the Fediverse, but you also
|
||||
still miss a lot of the "official" accounts that make a timeline actually
|
||||
stimulating. In my case, it's accounts of publications like the MIT Technology
|
||||
Review, Quanta Magazine, Scientific American, IoT-4-All, The Gradient and The
|
||||
Economist that really give me food for thought and make my social media
|
||||
experience worth the effort of scrolling through memes and rants.
|
||||
|
||||
Those accounts are only on Twitter and Facebook for now, or maybe on some RSS
|
||||
feed. But Platypush also provides integrations for [RSS
|
||||
feeds](https://docs.platypush.tech/platypush/plugins/rss.html) and
|
||||
[Mastodon](https://docs.platypush.tech/platypush/plugins/mastodon.html). So
|
||||
a bot that brings our social newspaper to our new doormat is just a few lines
|
||||
of code away.
|
||||
|
||||
Let's start by creating a new account on any Mastodon instance we like (if you
|
||||
don't host one yourself, just make sure that you are aligned with the instance
|
||||
admins and rules when it comes to bot activity). You can probably start your
|
||||
adventure with a bot hosted on one of the largest platforms - e.g.
|
||||
`mastodon.social`/`mastodon.online`. Specify username, email address and
|
||||
password for your bot, confirm the email address, login with the bot account,
|
||||
navigate to `Preferences` ⇛ `Development` ⇛ Create a `New Application`, give it
|
||||
full access (`read`+`write`+`follow`+`push`) to the account, and copy the
|
||||
provided `Access Token` - you'll need it soon.
|
||||
|
||||

|
||||
|
||||
It's also advised to navigate to `Profile` and tick the `This is a bot account`
|
||||
box, so people on the network know that there's not a human behind it. You can
|
||||
also provide a brief description of what profiles/feeds it mirrors so people
|
||||
know what to expect.
|
||||
|
||||

|
||||
|
||||
## The Platypush automation part
|
||||
|
||||
You can install and run the Platypush bot on any device, including a Raspberry
|
||||
Pi or an old Android phone running [Termux](https://termux.com/), as long as it
|
||||
can run a UNIX-like system and it has HTTP access to the instance that hosts
|
||||
your bot.
|
||||
|
||||
Install Python 3 and `pip` if they aren't installed already. Then install
|
||||
Platypush with the `rss` and `mastodon` integrations:
|
||||
|
||||
```bash
|
||||
[sudo] pip3 install 'platypush[rss,mastodon]'
|
||||
```
|
||||
|
||||
Now create a configuration file under `~/.config/platypush/config.yaml` that
|
||||
enables both the integrations:
|
||||
|
||||
```yaml
|
||||
mastodon:
|
||||
base_url: https://some.mastodon.instance
|
||||
access_token: YOUR-BOT-API-ACCESS-TOKEN
|
||||
|
||||
rss:
|
||||
poll_seconds: 300
|
||||
subscriptions:
|
||||
- https://blog.platypush.tech/rss
|
||||
- https://nitter.net/hackernoon/rss
|
||||
- https://nitter.net/TheHackersNews/rss
|
||||
- https://nitter.net/QuantaMagazine/rss
|
||||
- https://nitter.net/gradientpub/rss
|
||||
- https://nitter.net/IEEEorg/rss
|
||||
- https://nitter.net/ComputerSociety/rss
|
||||
- https://nitter.net/physorg_com/rss
|
||||
```
|
||||
|
||||
Twitter no longer supports RSS feeds for profiles or lists (so much again for
|
||||
the "Twitter❤️open protocols" narrative), and there's a multitude of (mostly
|
||||
paid or freemium) services out there that currently bridge that gap.
|
||||
Fortunately, the admins of `nitter.net` still do a good job in bridging Twitter
|
||||
timelines to RSS feeds, so in `rss.subscriptions` we use `nitter.net` URLs as a
|
||||
proxy to Twitter timelines.
|
||||
|
||||
Now create a script under `~/.config/platypush/scripts` named e.g.
|
||||
`mastodon_bot.py`. Its content can be something like the following:
|
||||
|
||||
```python
|
||||
import logging
|
||||
import re
|
||||
import requests
|
||||
|
||||
from platypush.event.hook import hook
|
||||
from platypush.message.event.rss import NewFeedEntryEvent
|
||||
from platypush.utils import run
|
||||
|
||||
logger = logging.getLogger('rss2mastodon')
|
||||
url_regex = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
|
||||
|
||||
|
||||
# Utility function to parse bit.ly links content
|
||||
def parse_bitly_link(link):
|
||||
rs = requests.get(link, allow_redirects=False)
|
||||
return rs.headers.get('Location', link)
|
||||
|
||||
|
||||
# Run this hook when the application receives a `NewFeedEntryEvent`
|
||||
@hook(NewFeedEntryEvent)
|
||||
def sync_feeds_to_mastodon(event, **context):
|
||||
item_url = event.url or ''
|
||||
content = event.title or ''
|
||||
source_name = event.feed_title or item_url
|
||||
|
||||
# Find and expand the shortened links
|
||||
bitly_links = set(re.findall(r'https?://bit.ly/[a-zA-Z0-9]+', content))
|
||||
for link in bitly_links:
|
||||
expanded_link = parse_bitly_link(link)
|
||||
content = content.replace(link, expanded_link)
|
||||
|
||||
# Find all the referenced URLs
|
||||
referenced_urls = url_regex.findall(content)
|
||||
|
||||
# Replace nitter.net prefixes with twitter.com
|
||||
if '/nitter.net/' in item_url:
|
||||
item_url = item_url.replace('/nitter.net/', '/twitter.com/')
|
||||
source_name += '@twitter.com'
|
||||
|
||||
if item_url and content:
|
||||
content = f'Originally posted by {source_name}: {item_url}\n\n{content}'
|
||||
if referenced_urls:
|
||||
content = f'Referenced link: {referenced_urls[-1]}\n{content}'
|
||||
|
||||
# Publish the status to Mastodon
|
||||
run(
|
||||
'mastodon.publish_status',
|
||||
status=content,
|
||||
visibility='public',
|
||||
)
|
||||
|
||||
logger.info(f'The URL has been successfully cross-posted: {item_url}')
|
||||
```
|
||||
|
||||
Now just start `platypush` with your local user:
|
||||
|
||||
```bash
|
||||
platypush
|
||||
```
|
||||
|
||||
The service will poll the configured RSS sources every five minutes (the
|
||||
interval is configurable through `rss.poll_seconds` in `config.yaml`). When a
|
||||
feed contains new items, a `NewFeedEntryEvent` is fired and your automation
|
||||
will be triggered, resulting in a new toot from your bot account.
|
||||
|
||||

|
||||
|
||||
If you like, you can follow
|
||||
[`crossbot`](https://social.platypush.tech/web/@crossbot), a Platypush-based
|
||||
bot that uses the automation described in this article to cross-post several
|
||||
Twitter accounts and RSS feeds to the `platypush.tech` Mastodon instance.
|
||||
|
||||
### Some performance considerations
|
||||
|
||||
Note that on the first execution the bot will start from an empty backlog, and
|
||||
depending on the number of items in your feeds you may end up with lots of API
|
||||
requests made to the instance. Depending on how large (and how bot-friendly)
|
||||
the instance is, this may result either in a (small) DoS against the instance,
|
||||
or your bot account being flagged/banned. A good idea may be to throttle the
|
||||
amount of posts that the bot publishes on every scan, especially on the first
|
||||
one. A few solutions (and common sense considerations) can work:
|
||||
|
||||
- Start a [Python
|
||||
`Timer`](https://www.section.io/engineering education/how to perform threading timer in python/)
|
||||
when a new item is received, if a timer is not already running. Every time a
|
||||
`NewFeedEntryEvent` is received, you can append the event to the queue, and
|
||||
upon a selected timeout the queue will be flushed and the most recent `n`
|
||||
items synchronized to Mastodon.
|
||||
|
||||
```python
|
||||
from queue import Queue
|
||||
from threading import Timer, RLock
|
||||
from time import time
|
||||
|
||||
from platypush.event.hook import hook
|
||||
from platypush.message.event.rss import NewFeedEntryEvent
|
||||
|
||||
# How often we should synchronize the feeds
|
||||
flush_interval = 30
|
||||
|
||||
# Maximum number of items to be flushed per iteration
|
||||
batch_size = 10
|
||||
|
||||
# Shared events cache
|
||||
events_cache = []
|
||||
|
||||
# Current timer and its creation lock
|
||||
feed_proc_timer = None
|
||||
feed_proc_lock = RLock()
|
||||
|
||||
|
||||
def feed_entries_publisher():
|
||||
# Only pick the most recent events
|
||||
events = sorted(
|
||||
filter(lambda e: e.published, events_cache),
|
||||
key=lambda e: e.published,
|
||||
reverse=True
|
||||
)[:batch_size]
|
||||
|
||||
for event in events:
|
||||
# Your event conversion and `mastodon.publish_status`
|
||||
# logic goes here
|
||||
try:
|
||||
...
|
||||
except:
|
||||
...
|
||||
|
||||
# Reset the events cache
|
||||
events_cache.clear()
|
||||
|
||||
|
||||
@hook(NewFeedEntryEvent)
|
||||
def push_feed_item_to_queue(event, **context):
|
||||
global feed_proc_timer
|
||||
|
||||
# Create and start a timer if it's not already running
|
||||
with feed_proc_lock:
|
||||
if (
|
||||
not feed_proc_timer or
|
||||
feed_proc_timer.finished.is_set()
|
||||
):
|
||||
feed_proc_timer = Timer(
|
||||
flush_interval, feed_entries_publisher
|
||||
)
|
||||
|
||||
feed_proc_timer.start()
|
||||
|
||||
# Push the event to the cache
|
||||
events_cache.append(event)
|
||||
```
|
||||
|
||||
- A producer/consumer solution can also work. Create a new hook upon
|
||||
`ApplicationStartedEvent` that starts a thread that reads feed item events
|
||||
from a queue and synchronizes them to your bot:
|
||||
|
||||
```python
|
||||
from queue import Queue, Empty
|
||||
from threading import Thread
|
||||
from time import time
|
||||
|
||||
from platypush.event.hook import hook
|
||||
from platypush.message.event.application import ApplicationStartedEvent
|
||||
from platypush.message.event.rss import NewFeedEntryEvent
|
||||
|
||||
# How often the events should be flushed, in seconds
|
||||
flush_interval = 30
|
||||
|
||||
# Maximum number of items to be flushed per iteration
|
||||
batch_size = 10
|
||||
|
||||
# Shared events queue
|
||||
events_queue = Queue()
|
||||
|
||||
|
||||
def feed_entries_publisher():
|
||||
events_cache = []
|
||||
|
||||
while True:
|
||||
# Read an event from the queue
|
||||
try:
|
||||
events_cache.append(
|
||||
events_queue.get(timeout=0.5)
|
||||
)
|
||||
except Empty:
|
||||
continue
|
||||
|
||||
# Only pick the most recent events
|
||||
events = sorted(
|
||||
filter(lambda e: e.published, events_cache),
|
||||
key=lambda e: e.published,
|
||||
reverse=True
|
||||
)[:batch_size]
|
||||
|
||||
for event in events:
|
||||
# Your event conversion and `mastodon.publish_status`
|
||||
# logic goes here
|
||||
try:
|
||||
...
|
||||
except:
|
||||
...
|
||||
|
||||
# Reset the events cache
|
||||
events_cache.clear()
|
||||
|
||||
|
||||
@hook(ApplicationStartedEvent)
|
||||
def on_application_started(*_, **__):
|
||||
# Start the feed processing thread
|
||||
Thread(target=feed_entries_publisher).start()
|
||||
|
||||
|
||||
@hook(NewFeedEntryEvent)
|
||||
def push_feed_item_to_queue(event, **context):
|
||||
# Just push the event to the processor
|
||||
events_queue.put(event)
|
||||
```
|
||||
|
||||
- A workaround for bootstrapping your bot could be to perform a _slow boot_.
|
||||
Add one feed at the time to the configuration, and restart the service when
|
||||
the latest feed has been synchronized, until all the items have been
|
||||
published.
|
||||
|
||||
After the first run the feeds' latest timestamps are updated and they won't be
|
||||
reprocessed entirely upon restart. However, it's generally a good idea to keep
|
||||
your bot light. If it posts too much, it may end up polluting many timelines, as
|
||||
well as fill up a lot of storage space on many instances. So apply some common
|
||||
sense: don't cross-post the whole Twitter, or your cross-posting bot will not
|
||||
add much value.
|
||||
|
||||
## The advantages of a cross-posting bot
|
||||
|
||||
If used and configured responsibly, a cross-posting bot can vastly improve the
|
||||
social experience on the Fediverse.
|
||||
|
||||
It brings relevant content shared on other platforms to the Fediverse, spinning
|
||||
off discussions and interactions outside of the mainstream centralized
|
||||
platforms.
|
||||
|
||||
It's also a quick and efficient way to bootstrap your new instance. Many new
|
||||
administrators are faced with a dilemma when it comes to kickstarting their
|
||||
instances. Either they go the conventional slow way (advertise their instance
|
||||
to increase their user base, and manually discover and follow accounts on other
|
||||
instances in order to slowly populate the federated timeline, hoping that users
|
||||
won't leave in the meantime), or they associate to one or more _relays_ (some
|
||||
kind of _instance aggregators_ that bring traffic from multiple instances to
|
||||
the federated timeline), just to be overwhelmed by an endless torrent of mostly
|
||||
irrelevant toots that will quickly fill up their disk storage. Such a bot is an
|
||||
efficient way in between: it populates your instance with the content that you
|
||||
want, it brings in some hashtags and links from Twitter that you may decide or
|
||||
not to boost on your instance, and it attracts people that are looking for
|
||||
curated lists of content on the Fediverse.
|
||||
|
||||
## ...but the Fediverse isn't all that rosy either...
|
||||
|
||||
After so many praises of ActivityPub, Mastodon and its brothers, the time has
|
||||
come to highlight some of their drawbacks.
|
||||
|
||||
I briefly mentioned _relays_ in the article, and that's not a coincidence.
|
||||
Relays, if implemented, maintained and adopted properly, can be the killing
|
||||
feature of the Fediverse. No more cold bootstrapping would be required for new
|
||||
instances: as long as they share common interests and adhere to similar rules
|
||||
as other instances, they can easily federate with one another by joining a
|
||||
relay.
|
||||
|
||||
A relay is basically a server with a list of instance URLs. It subscribes to
|
||||
the local timelines of the instances and it broadcasts their activities over
|
||||
ActivityPub. Therefore, all the instances that are part of the same relay can
|
||||
see all the public posts published on all the other instances in their
|
||||
federated timeline.
|
||||
|
||||
Amazing, isn't it? Except that, as of today, the experience with relays is far
|
||||
from this vision of a curated and manageable aggregator of instance. There are
|
||||
[only a few usable open-source relay
|
||||
projects](https://github.com/distributopia/fediverse-relays), and most of them
|
||||
are still in a beta/pre-production stage. Most of the URLs you find on Reddit
|
||||
or on forums are no longer working. An up-to-date list of active relays is
|
||||
[available here](https://the-federation.info/activityrelay), it includes about
|
||||
40 nodes as of today, and after trying most of them I can tell that they fall
|
||||
into three categories:
|
||||
|
||||
- About half of them will turn your timeline into an endless torrent of spam
|
||||
and saturate your database. Most of them automatically accept any relay
|
||||
requests, and with no inbound filter spammers can easily take over. Also,
|
||||
with no clear mission/purpose/shared interests or languages, and poor
|
||||
filtering by topics and languages provided by the platform, after relaying
|
||||
you can expected your federated timeline to turn into a Babylon with all the
|
||||
languages and topics in this world. My database storage inflated by ~40 MB
|
||||
just a couple of minutes after joining the most populated relay.
|
||||
|
||||
- A third of the URLs points to servers that no longer seem to accept relay
|
||||
requests, or with nearly no content.
|
||||
|
||||
- The remaining ~15% points to a couple of relays that actually push
|
||||
not-so-spammy content in a manageable way.
|
||||
|
||||
At the time being I have joined those relays, but there's really no concept of
|
||||
curation/aggregation yet at the current stage. To me, relays should be to
|
||||
Fediverse instances what OPML is to RSS feeds and podcasts: a curated way to
|
||||
aggregate sources that share common traits, not a chaotic party where everybody
|
||||
is allowed to join. We don't seem to be at that stage yet.
|
||||
|
||||
It also doesn't help that the two main instances (`mastodon.online` and
|
||||
`mastodon.social`) aren't part of any relays. The only way to get posts from
|
||||
the largest instances pumped into yours is to follow individual accounts. I
|
||||
understand the challenges of having to moderate large-scale relays involving
|
||||
the two official instances, but I also think that if we keep the largest
|
||||
instances out of the relay game then we can't expect relaying to improve much.
|
||||
|
||||
On the contrary, I see the risk for things to evolve in a direction where large
|
||||
instances don't have any incentives in joining a relay, while relays are mostly
|
||||
run by hobbyists and end up attracting a long tail of unfiltered and
|
||||
non-curated traffic from all the other small instances. In such a scenario,
|
||||
most of the people will simply open their accounts on the largest instances,
|
||||
because that's where most of the things happen anyway. And then things will
|
||||
just swing back towards centralization. That's why I don't get those who praise
|
||||
decentralized social networks and then simply move to one of the two main
|
||||
Mastodon instances. Supporting decentralization isn't just about migrating from
|
||||
a large centralized platform to a smaller one. It's a much better idea to
|
||||
support a smaller instance: it'll still act as a gateway to follow and interact
|
||||
with anyone on the Fediverse anyway, while keeping the content really
|
||||
decentralized.
|
||||
|
||||
All in all, however, I still believe that the Fediverse is the only possible
|
||||
future for social media that is both scalable, portable and transparent. The
|
||||
current immature state of the relaying technology will probably be fixed one
|
||||
iteration at the time. And, even if Mastodon turns out to be a new centralized
|
||||
titan in the future, we can simply move our data and accounts to another
|
||||
instance running another server, just like we would move a website from a
|
||||
hosting service to another. Because, after all, data portability and
|
||||
interoperability is all the web was supposed to be about.
|
||||
Loading…
Add table
Add a link
Reference in a new issue