22 KiB
Triggering events based on the presence of people has been the dream of many geeks and DIY automation junkies for a while. Having your house to turn the lights on or off when you enter or exit your living room is an interesting application, for instance. Most of the solutions out there to solve these kinds of problems, even more high-end solutions like the Philips Hue sensors, detect motion, not actual people presence — which means that the lights will switch off once you lay on your couch like a sloth. The ability to turn off music and/or tv when you exit the room and head to your bedroom, without the hassle of switching all the buttons off, is also an interesting corollary. Detecting the presence of people in your room while you’re not at home is another interesting application.
Thermal cameras coupled with deep neural networks are a much more robust strategy to actually detect the presence of people. Unlike motion sensors, they will detect the presence of people even when they aren’t moving. And unlike optical cameras, they detect bodies by measuring the heat that they emit in the form of infrared radiation, and are therefore much more robust — their sensitivity doesn’t depend on lighting conditions, on the position of the target, or the colour. Before exploring the thermal camera solution, I tried for a while to build a model that instead relied on optical images from a traditional webcam. The differences are staggering: I trained the optical model on more than ten thousands 640x480 images taken all through a week in different lighting conditions, while I trained the thermal camera model on a dataset of 900 24x32 images taken during a single day. Even with more complex network architectures, the optical model wouldn’t score above a 91% accuracy in detecting the presence of people, while the thermal model would achieve around 99% accuracy within a single training phase of a simpler neural network. Despite the high potential, there’s not much out there in the market — there’s been some research work on the topic (if you google “people detection thermal camera” you’ll mostly find research papers) and a few high-end and expensive products for professional surveillance. In lack of ready-to-go solutions for my house, I decided to take on my duty and build my own solution — making sure that it can easily be replicated by anyone.
Prepare the hardware
For this example we'll use the following hardware:
-
A RaspberryPi (cost: around $35). In theory any model should work, but it’s probably not a good idea to use a single-core RaspberryPi Zero for machine learning tasks — the task itself is not very expensive (we’ll only use the Raspberry for doing predictions on a trained model, not to train the model), but it may still suffer some latency on a Zero. Plus, it may be really painful to install some of the required libraries (like Tensorflow or OpenCV) on the
arm6architecture used by the RaspberryPi Zero. Any better performing model (from RPi3 onwards) should definitely do the job. -
A thermal camera. For this project, I’ve used the MLX90640 Pimoroni breakout camera (cost: $55), as it’s relatively cheap, easy to install, and it provides good results. This camera comes in standard (55°) and wide-angle (110°) versions. I’ve used the wide-angle model as the camera monitors a large living room, but take into account that both have the same resolution (32x24 pixels), so the wider angle comes with the cost of a lower spatial resolution. If you want to use a different thermal camera there’s not much you’ll need to change, as long as it comes with a software interface for RaspberryPi and it’s compatible with Platypush.
Setting up the MLX90640 on your RaspberryPi if you have a Breakout Garden it’s easy as a pie. Fit the Breakout Garden on top of your RaspberryPi. Fit the camera breakout into an I2C slot. Boot the RaspberryPi. Done. Otherwise, you can also connect the device directly to the RaspberryPi I2C interface, either using the right hardware PINs or the software emulation layer.
Prepare the software
I tested my code on Raspbian, but with a few minor modifications it should be easily adaptable to any distribution installed on the RaspberryPi.
The software support for the thermal camera requires a bit of work. The MLX90640 doesn’t come (yet) with a Python ready-to-use interface, but a C++ open-source driver is provided - and that's the driver that is wrapped by the Platypush integration. Instructions to install it:
# Install the dependencies
[sudo] apt-get install libi2c-dev
# Enable the I2C interface
echo dtparam=i2c_arm=on | sudo tee -a /boot/config.txt
# It's advised to configure the SPI bus baud rate to
# 400kHz to support the higher throughput of the sensor
echo dtparam=i2c1_baudrate=400000 | sudo tee -a /boot/config.txt
# A reboot is required here if you didn't have the
# options above enabled in your /boot/config.txt
[sudo] reboot
# Clone the driver's codebase
git clone https://github.com/pimoroni/mlx90640-library
cd mlx90640-library
# Compile the rawrgb example
make clean
make bcm2835
make I2C_MODE=LINUX examples/rawrgb
If it all went well you should see an executable named rawrgb under the examples directory. If you run it you should
see a bunch of binary data — that’s the raw binary representation of the frames captured by the camera. Remember where
it is located or move it to a custom bin folder, as it’s the executable that platypush will use to interact with the
camera module.
This post assumes that you have already installed and configured Platypush on your system. If not, head to my post on getting started with Platypush, the readthedocs page, the Gitlab page or the wiki.
Install also the Python dependencies for the HTTP server, the MLX90640 plugin and Tensorflow:
[sudo] pip install 'platypush[http,tensorflow,mlx90640]'
Tensorflow may also require some additional dependencies installable via apt-get:
[sudo] apt-get install python3-numpy \
libatlas-base-dev \
libblas-dev \
liblapack-dev \
python3-dev \
gfortran \
python3-setuptools \
python3-scipy \
python3-h5py
Heading to your computer (we'll be using it for building the model that will be used on the RaspberryPi), install OpenCV, Tensorflow and Jupyter and my utilities for handling images:
# For image manipulation
[sudo] pip install opencv
# Install Jupyter notebook to run the training code
[sudo] pip install jupyterlab
# Then follow the instructions at https://jupyter.org/install
# Tensorflow framework for machine learning and utilities
[sudo] pip install tensorflow numpy matplotlib
# Clone my repository with the image and training utilities
# and the Jupyter notebooks that we'll use for training.
git clone https://github.com/BlackLight/imgdetect-utils ~/projects/imgdetect-utils
Capture phase
Now that you’ve got all the hardware and software in place, it’s time to start capturing frames with your camera and use
them to train your model. First, configure
the MLX90640 plugin in your
Platypush configuration file (by default, ~/.config/platypush/config.yaml):
# Enable the webserver
backend.http:
enabled: True
camera.ir.mlx90640:
fps: 16 # Frames per second
rotate: 270 # Can be 0, 90, 180, 270
rawrgb_path: /path/to/your/rawrgb
Restart the service, and if you haven't already create a user from the web interface at http://your-rpi:8008. You
should now be able to take pictures through the API:
curl -XPOST -H 'Content-Type: application/json' -d '
{
"type":"request",
"action":"camera.ir.mlx90640.capture",
"args": {
"output_file":"~/snap.png",
"scale_factor":20
}
}' -u 'username:password' http://localhost:8008/execute
If everything went well, the thermal picture should be stored under ~/snap.png. In my case it looks like this while
I’m in standing front of the sensor:

Notice the glow at the bottom-right corner — that’s actually the heat from my RaspberryPi 4 CPU. It’s there in all the images I take, and you may probably see similar results if you mounted your camera on top of the Raspberry itself, but it shouldn’t be an issue for your model training purposes.
If you open the web panel (http://your-host:8008) you’ll also notice a new tab, represented by the sun icon, that you
can use to monitor your camera from a web interface.

You can also monitor the camera directly outside of the webpanel by pointing your browser to
http://your-host:8008/camera/ir/mlx90640/stream?rotate=270&scale_factor=20.
Now add a cronjob to your config.yaml to take snapshots every minute:
cron.ThermalCameraSnapshotCron:
cron_expression: '* * * * *'
actions:
- action: camera.ir.mlx90640.capture
args:
output_file: "${__import__(’datetime’).datetime.now().strftime(’/home/pi/datasets/people_detect/images/%Y-%m-%d_%H-%M-%S.jpg’)}"
grayscale: true
Or directly as a Python script under e.g. ~/.config/platypush/thermal.py (make sure that ~/.config/platypush/__init__.py also exists so the folder is recognized as a Python module):
from datetime import datetime
from platypush.cron import cron
from platypush.utils import run
@cron('* * * * *')
def take_thermal_picture(**context):
run('camera.ir.mlx90640.capture', grayscale=True,
output_file=datetime.now().strftime('/home/pi/datasets/people_detect/images/%Y-%m-%d_%H-%m-%S.jpg'))
The images will be stored under /home/pi/datasets/people_detect/images (make sure that the directory exists before starting
the service) in the format YYYY-mm-dd_HH-MM-SS.jpg. No scale factor is applied — even if the images will be tiny we’ll
only need them to train our model. Also, we’ll convert the images to grayscale — the neural network will be lighter and
actually more accurate, as it will only have to rely on one variable per pixel without being tricked by RGB
combinations.
Restart Platypush and verify that every minute a new picture is created under your images directory. Let it run for a few hours or days until you’re happy with the number of samples. Try to balance the numbers of pictures with no people in the room and those with people in the room, trying to cover as many cases as possible — e.g. sitting, standing in different points of the room etc. As I mentioned earlier, in my case I only needed less than 1000 pictures with enough variety to achieve accuracy levels above 99%.
Labelling phase
Once you’re happy with the number of samples you’ve taken, copy the images over to the machine you’ll be using to train your model (they should be all small JPEG files weighing under 500 bytes each). Copy them to your local machine:
BASEDIR=~/datasets/people_detect
mkdir -p "$BASEDIR"
# Copy the images
scp -r pi@raspberry:/home/pi/datasets/people_detect ~
IMGDIR="$BASEDIR/images"
# This directory will contain the raw numpy training
# data parsed from the images (useful if you want to
# re-train the model without having to reprocess all
# the images)
DATADIR="$BASEDIR/data"
mkdir -p "$IMGDIR"
mkdir -p "$DATADIR"
# Create the labels for the images. Each label is a
# directory under $IMGDIR
mkdir "$IMGDIR/negative"
mkdir "$IMGDIR/positive"
Once the images have been copied, and the directories for the labels created,
run the label.py script provided in the repository to interactively label the
images:
UTILS_DIR=~/projects/imgdetect-utils
cd "$UTILS_DIR"
python utils/label.py -d "$IMGDIR" --scale-factor 10
Each image will open in a new window and you can label it by typing either 1 (negative) or 2 (positive) - the label names are gathered from the names of the directories you created at the previous step:

At the end of the procedure the negative and positive directories under the
images directory should have been populated.
Training phase
Once we’ve got all the labelled images it’s time to train our model. A
train.ipynb
Jupyter notebook is provided under notebooks/ir and it should be
relatively self-explanatory:
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Define the dataset directory - replace it with the path on your local
# machine where you have stored the previously labelled dataset.
dataset_dir = os.path.join(os.path.expanduser('~'), 'datasets', 'people_detect')
# Define the size of the input images. In the case of an
# MLX90640 it will be (24, 32) for horizontal images and
# (32, 24) for vertical images
image_size = (32, 24)
# Image generator batch size
batch_size = 64
# Number of training epochs
epochs = 5
# Instantiate a generator that puts 30% of the images into the validation set
# and normalizes their pixel values between 0 and 1
generator = ImageDataGenerator(rescale=1./255, validation_split=0.3)
train_data = generator.flow_from_directory(dataset_dir,
target_size=image_size,
batch_size=batch_size,
subset='training',
class_mode='categorical',
color_mode='grayscale')
test_data = generator.flow_from_directory(dataset_dir,
target_size=image_size,
batch_size=batch_size,
subset='validation',
class_mode='categorical',
color_mode='grayscale')
After initializing the generators, let's take a look at a sample of 25 images from the training set together with their labels:
index_to_label = {
index: label
for label, index in train_data.class_indices.items()
}
plt.figure(figsize=(10, 10))
batch = train_data.next()
for i in range(min(25, len(batch[0]))):
img = batch[0][i]
label = index_to_label[np.argmax(batch[1][i])]
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# Note the np.squeeze call - matplotlib can't
# process grayscale images unless the extra
# 1-sized dimension is removed.
plt.imshow(np.squeeze(img))
plt.xlabel(label)
plt.show()
You should see an image like this:

Let's now declare a model and train it on the given training set:
model = keras.Sequential([
# Layer 1: flatten the input images
keras.layers.Flatten(input_shape=image_size),
# Layer 2: fully-connected layer with 80% the neurons as the input images
# and RELU activation function
keras.layers.Dense(round(0.8 * image_size[0] * image_size[1]),
activation=tf.nn.relu),
# Layer 2: fully-connected layer with 30% the neurons as the input images
# and RELU activation function
keras.layers.Dense(round(0.3 * image_size[0] * image_size[1]),
activation=tf.nn.relu),
# Layer 3: fully-connected layer with as many units as the output labels
# and Softmax activation function
keras.layers.Dense(len(train_data.class_indices),
activation=tf.nn.softmax)
])
# Compile the model for classification, use the Adam optimizer and pick
# accuracy as optimization metric
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# Train the model in batches
history = model.fit(
train_data,
steps_per_epoch=train_data.samples/batch_size,
validation_data=test_data,
validation_steps=test_data.samples/batch_size,
epochs=epochs
)
# Example output:
# Epoch 1/5 loss: 0.2529 - accuracy: 0.9196 - val_loss: 0.0543 - val_accuracy: 0.9834
# Epoch 2/5 loss: 0.0572 - accuracy: 0.9801 - val_loss: 0.0213 - val_accuracy: 0.9967
# Epoch 3/5 loss: 0.0254 - accuracy: 0.9915 - val_loss: 0.0080 - val_accuracy: 1.0000
# Epoch 4/5 loss: 0.0117 - accuracy: 0.9979 - val_loss: 0.0053 - val_accuracy: 0.9967
# Epoch 5/5 loss: 0.0058 - accuracy: 1.0000 - val_loss: 0.0046 - val_accuracy: 0.9983
We can now see how the accuracy of the model progressed over the iteration:
epochs = history.epoch
accuracy = history.history['accuracy']
fig = plt.figure()
plot = fig.add_subplot()
plot.set_xlabel('epoch')
plot.set_ylabel('accuracy')
plot.plot(epochs, accuracy)
The output should look like this:
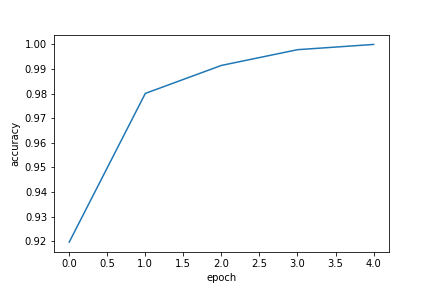
By constraining the problem properly (i.e. translating "detect people in an image" to "infer the presence of people by telling if there are more white halos than usual in a small grayscale image") we have indeed managed to achieve high levels of accuracy both on the training and validation set despite using a relatively small dataset.
Deploying the model
Once you are happy with the model, it's time to save it so it can be deployed to your RaspberryPi for real-time predictions:
def model_save(model, target, labels=None, overwrite=True):
import json
import pathlib
# Check if we should save it like a .h5/.pb file or as a directory
model_dir = pathlib.Path(target)
if str(target).endswith('.h5') or \
str(target).endswith('.pb'):
model_dir = model_dir.parent
# Create the model directory if it doesn't exist
pathlib.Path(model_dir).mkdir(parents=True, exist_ok=True)
# Save the Tensorflow model using the .save method
model.save(target, overwrite=overwrite)
# Save the label names of your model in a separate JSON file
if labels:
labels_file = os.path.join(model_dir, 'labels.json')
with open(labels_file, 'w') as f:
f.write(json.dumps(list(labels)))
model_dir = os.path.expanduser('~/models/people_detect')
model_save(model, model_dir,
labels=train_data.class_indices.keys(), overwrite=True)
If you managed to execute the whole notebook then you’ll have your model saved under ~/models/people_detect.
You can now copy it over to the RaspberryPi and use it to do predictions (first create ~/models on the RaspberryPi
if it's not available already):
scp -r ~/models/people_detect pi@raspberry:/home/pi/models
Detect people in the room
Once the Tensorflow model has been deployed to the RaspberryPi you can quickly test how it performs against some
pictures taken on the device using
the tensorflow.predict
method:
curl -XPOST -u 'user:pass' -H 'Content-Type: application/json' -d '
{
"type":"request",
"action":"tensorflow.predict",
"args": {
"inputs": "~/datasets/people_detect/positive/some_image.jpg",
"model": "~/models/people_detect"
}
}' http://your-raspberry-pi:8008/execute
Expected output:
{
"id": "<response-id>",
"type": "response",
"target": "http",
"origin": "raspberrypi",
"response": {
"output": {
"model": "~/models/people_detect",
"outputs": [
{
"negative": 0,
"positive": 1
}
],
"predictions": [
"positive"
]
},
"errors": []
}
}
Once the structure of the response is clear, we can replace the previous cronjob that stores pictures at regular
intervals with a new one that captures pictures and feeds them to the previously trained model to make predictions (I'll
use a Python script stored under ~/.config/platypush/scripts in this case, but it will also work with a cron defined
in YAML in config.yaml) and, for example, turns on the lights when presence is detected and turns them off when
presence is no longer detected (I'll use
the light.hue plugin in this example):
import os
from platypush.context import get_plugin
from platypush.cron import cron
@cron('* * * * * */30')
def check_presence(**context):
# Get plugins by name
camera = get_plugin('camera.ir.mlx90640')
tensorflow = get_plugin('tensorflow')
lights = get_plugin('light.hue')
image_file = '/tmp/frame.jpg'
model_file = os.path.expanduser('~/models/people_detect/saved_model.h5')
camera.capture_image(
image_file=image_file, grayscale=True)
prediction = tensorflow.predict(
inputs=image_file, model=model_file)['predictions'][0]
if prediction == 'positive':
lights.on()
else:
lights.off()
Restart the service and let it run. Every 30 seconds the cron will run, take a picture, check if people are detected in that picture and turn the lights on/off accordingly.
What's next?
That’s your call! Feel free to experiment with more elaborate rules, for example to change the status of the music/video playing in the room when someone enters, using Platypush media plugins. Or say a custom good morning text when you first enter the room in the morning. Or build your own surveillance system to track the presence of people when you’re not at home. Or enhance the model to detect also the number of people in the room, not only the presence. Or you can combine it with an optical flow sensor, distance sensor, laser range sensor or optical camera (platypush provides plugins for many of them) to build an even more robust system that also detects and tracks movements or proximity to the sensor, and so on.